SystemVerilog语法详解
本文最后更新于:2026年1月14日 下午
本文讲解顺序与 IEEE Standard for SystemVerilog 保持一致。
第一章 基本构成元素
第二章 调度语义
SystemVerilog 是一种并行编程语言,其特定语言结构的执行通过并行执行的代码块或进程来定义。理解哪些执行顺序对用户有保证、哪些执行顺序具有不确定性至关重要。
尽管 SystemVerilog 的用途不仅限于仿真,但该语言的语义是基于仿真定义的,其他所有概念均源自这一基础定义。
事件仿真
SystemVerilog 描述由相互关联的执行线程或进程组成。进程是可被执行的对象,可具备状态,并能响应输入变化以产生输出。进程是并行调度的元素,例如 initial 过程。进程的示例包括但不限于:原语;initial、always、always_comb、always_latch 和 always_ff 过程;连续赋值;异步任务;以及过程赋值语句。
在仿真的系统描述中,线网或变量的每次状态变化均被视为更新事件。进程对更新事件具有敏感性。当执行更新事件时,所有对该事件敏感的进程将以任意顺序被考虑进行执行。进程的执行本身也是一个事件,称为执行事件。
评估事件还包括 PLI 回调,这些是执行模型中的特定点,仿真内核可以在此处调用 PLI 应用程序例程。除了事件之外,仿真器的另一个关键方面是时间。术语“仿真时间”用于指代仿真器维护的时间值,以模拟被仿真系统描述所需的实际时间。为了全面支持清晰且可预测的交互,单个时间槽被划分为多个区域,可以在这些区域中调度事件,以提供特定类型执行的顺序。这使得属性和检查器能够在被测设计处于稳定状态时采样数据。属性表达式可以安全地评估,测试平台可以以零延迟对属性和检查器做出反应,所有这些都以可预测的方式进行。同样的机制还允许设计中的非零延迟、时钟传播和/或激励与响应代码与周期精确的描述自由且一致地混合使用。
分层事件调度器
每个事件都有一个且仅有一个仿真执行时间,在仿真过程中的任何给定点,该时间可以是当前时间或未来的某个时间。特定时间的所有已调度事件定义了一个时间槽。仿真按时间顺序执行并移除当前仿真时间槽中的所有事件,然后移动到下一个非空时间槽。此过程保证了仿真器在时间上永远不会倒退。
时间段被划分为一组有序区域,具体如下:
- Preponed
- Pre-Active
- Active
- Inactive
- Pre-NBA
- NBA
- Post-NBA
- Pre-Observed
- Observed
- Post-Observed
- Reactive
- Re-Inactive
- Pre-Re-NBA
- Re-NBA
- Post-Re-NBA
- Pre-Postponed
- Postponed
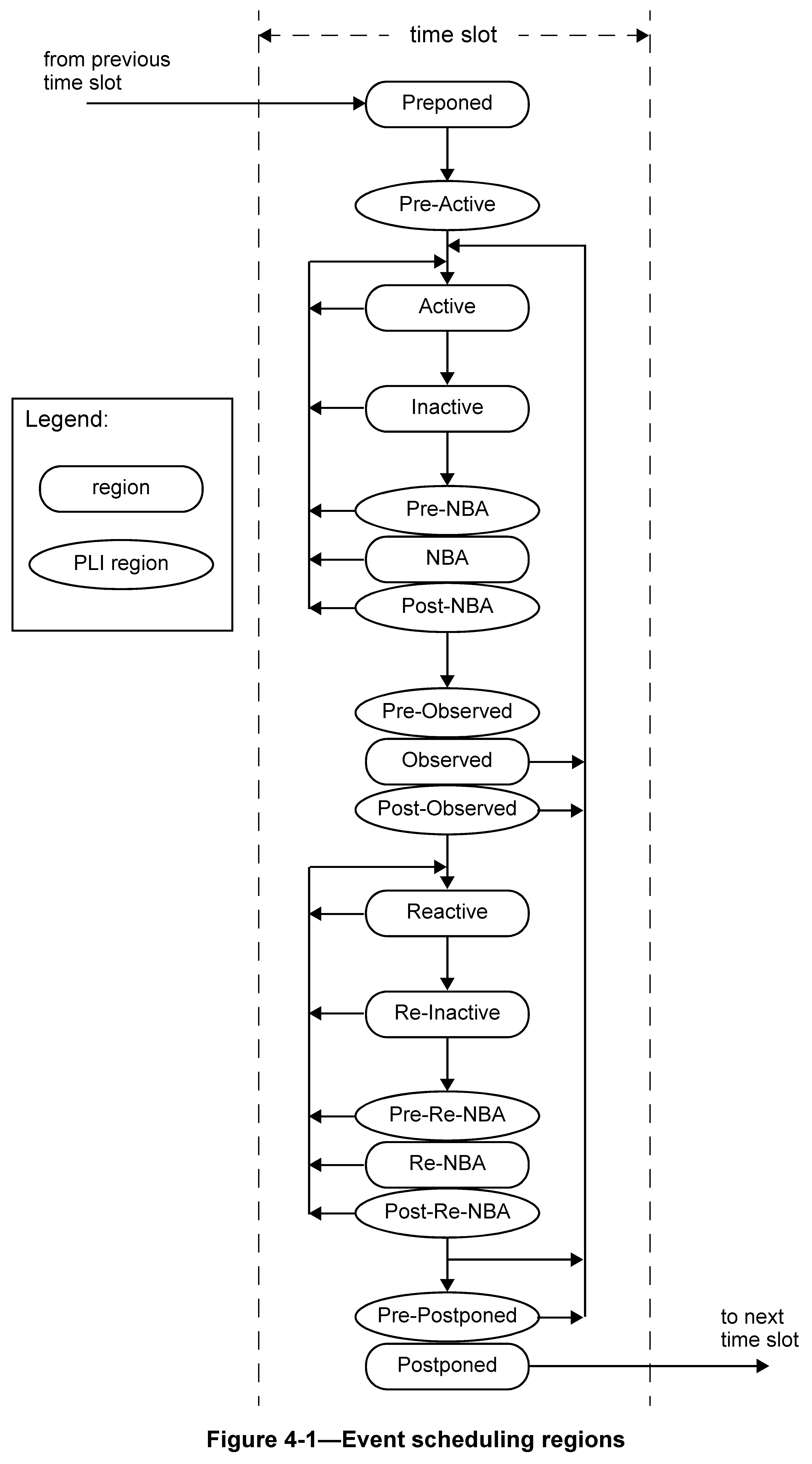
活动区域集与反应区域集
事件区域有两个重要的分组,用于帮助定义 SystemVerilog 活动的调度,即 active 区域集和 reactive 区域集。
- 在 Active, Inactive, Pre-NBA, NBA 和 Post-NBA 区域中调度的事件属于 active 区域集事件
- 在 Reactive, Re-Inactive, Pre-Re-NBA, Re-NBA 和 Post-Re-NBA 中调度的事件属于 reactive 区域集事件
- Active, Inactive, Pre-NBA, NBA, Post-NBA, Pre-Observed, Observed, Post-Observed, Reactive, Re-Inactive, Pre-Re-NBA, Re-NBA, Post-Re-NBA 和 Pre-Postponed 被称为迭代区域
除了 active 区域集和 reactive 区域集外,每个时间槽的所有事件区域还可以归类为仿真区域或 PLI 区域。
仿真区域
一个时间槽的仿真区域包括 Preponed, Active, Inactive, NBA, Observed, Reactive, Re-Inactive, Re-NBA 和 Postponed 区域。
Preponed 事件区域
#1step 采样延迟提供了在当前时间槽进入之前立即采样数据的能力。#1step 采样等同于在当前时间槽的 Preponed 区域中获取数据样本。在 Preponed 区域中采样等效于在前一个时间槽的 Postponed 区域中采样。
Preponed 区域 PLI 事件也在此区域中调度。
Active 事件区域
Active 区域包含当前正在评估的 active 区域集事件,可以按任意顺序处理。
Inactive 事件区域
Inactive 区域包含在所有 Active 事件处理完毕后需要评估的事件。
如果在 Active 区域集中执行事件,显式的 #0 延迟控制会要求进程挂起,并将一个事件调度到当前时间槽的 Inactive 区域中,以便进程可以在下一次从 Inactive 到 Active 的迭代中恢复。
NBA 事件区域
NBA(nonblocking assignment update,非阻塞赋值更新)区域包含在所有 Inactive 事件处理完毕后需要评估的事件。
如果在 Active 区域集中执行事件,非阻塞赋值会在 NBA 区域中创建一个事件,调度到当前或稍后的仿真时间。
Observed 事件区
Observed 区用于在属性表达式被触发时对其进行评估。在属性评估期间,通过/失败代码应调度至当前时间槽的 Reactive 区内。Observed 区不允许进行 PLI 回调。
Reactive 事件区
Reactive 区容纳当前正在评估的 reactive 区域集事件,这些事件可按任意顺序处理。检查器中的阻塞赋值、程序块以及并发断言动作块中指定的代码均被调度至 Reactive 区。Reactive 区是 Active 区在 reactive 区域集中的对应区域。
Re-Inactive 事件区
Re-Inactive 区用于存放所有 Reactive 事件处理完毕后待评估的事件。
若在 Reactive 区集合中执行事件,显式的 #0 延迟控制将要求挂起进程,并将事件调度至当前时间槽的 Re-Inactive 区,以便进程可在下一轮 Re-Inactive 到 Reactive 迭代中恢复执行。Re-Inactive 区是 Inactive 区在 reactive 区域集中的对应区域。
Re-NBA 事件区
Re-NBA 区用于存放所有 Re-Inactive 事件处理完毕后待评估的事件。
若在 reactive 区域集中执行事件,非阻塞赋值会在为当前或后续仿真时间调度的 Re-NBA 更新区中创建事件。Re-NBA 区是 NBA 区在 reactive 区域集中的对应区域。
Postponed 事件区
$monitor、$strobe 及其他类似事件均被调度至 Postponed 区。
一旦进入 Postponed 区,当前时间槽内不允许再发生任何新的数值变化。在该区域内,禁止向任何线网或变量写入数值,也不得在当前时间槽内任何先前区域调度事件。Postponed 区 PLI 事件同样在此区域调度。
PLI 区域
除可调度 PLI 回调的仿真区域外,还存在特定的 PLI 专属区域。时间槽的 PLI 区域包括:Preponed, Pre-Active, Pre-NBA, Post-NBA,
Pre-Observed, Post-Observed, Pre-Re-NBA, Post-Re-NBA 和 Pre-Postponed
Preponed PLI 区
预延迟区提供PLI回调控制点,允许PLI应用程序例程在任何线网或变量状态改变前访问当前时间槽的数据。在该区域内,禁止向任何线网或变量写入数值,也不得在当前时间槽内任何其他区域调度事件。
注:PLI当前不在预置区域调度回调。
Pre-Active PLI 区域
预激活区域提供了一个PLI回调控制点,允许PLI应用程序例程在评估激活区域的事件之前读取和写入数值并创建事件
Pre-NBA PLI 区域
预NBA区域提供了一个PLI回调控制点,允许PLI应用程序例程在评估NBA区域的事件之前读取和写入数值并创建事件
Post-NBA PLI 区域
后NBA区域提供了一个PLI回调控制点,允许PLI应用程序例程在评估NBA区域的事件之后读取和写入数值并创建事件
Pre-Observed PLI 区域
预观测区域提供了一个PLI回调控制点,允许PLI应用程序例程在激活区域集稳定后读取数值。在此区域内,禁止向任何网络或变量写入数值,或在当前时间槽内调度事件。
Post-Observed PLI 区域
后观测区域提供了一个PLI回调控制点,允许PLI应用程序例程在评估属性(在观测区域或更早区域)后读取数值。
注:PLI当前不在后观测区域调度回调。
Pre-Re-NBA PLI 区域
预重NBA区域提供了一个PLI回调控制点,允许PLI应用程序例程在评估重NBA区域的事件之前读取和写入数值并创建事件
Post-Re-NBA PLI 区域
后重NBA区域提供了一个PLI回调控制点,允许PLI应用程序例程在评估重NBA区域的事件之后读取和写入数值并创建事件
Pre-Postponed PLI 区域
预推迟区域提供了一个PLI回调控制点,允许PLI应用程序例程在处理除推迟区域外的所有其他区域后读取和写入数值并创建事件。
Postponed PLI 区域
推迟区域提供了一个PLI回调控制点,允许PLI应用程序例程在处理所有其他区域后创建只读事件。PLI的cbReadOnlySynch及其他类似事件在推迟区域中调度。
仿真调度参考算法
1 | |
确定性与不确定性
特定的调度顺序被确保:
- 在 begin-end 块内的语句应按照其在该块中出现的顺序执行。特定 begin-end 块中的语句执行可以暂停,以便执行模型中的其他进程;但无论如何,begin-end 块中的语句不得以源文件中出现顺序之外的任何顺序执行。
- NBA 的评估应按照语句执行的顺序进行。
考虑以下示例:1
2
3
4
5
6
7module test;
logic a;
initial begin
a <= 0;
a <= 1;
end
endmodule
当该代码块执行时,会有两个事件被添加到 NBA(非阻塞赋值)区域。先前的规则要求这些事件按照执行顺序(在顺序执行的 begin-end 块中即源码顺序)进入事件区域。而此规则要求它们从 NBA 区域取出时,同样按照执行顺序进行处理。
因此,在仿真时间0结束时,变量 a 将先被赋值为 0,随后被赋值为 1。
不确定性:
- 活跃事件可以从 Active 事件区或 Reactive 事件区中取出并以任意顺序处理。- 过程块中不包含时间控制结构的语句不一定作为一个事件执行
- 在评估过程语句的任何时刻,模拟器都可能暂停执行,并将部分完成的事件作为待处理事件放入事件区。这样做的效果是允许进程执行的交错,尽管交错执行的顺序是不确定的,且不受用户控制。
竞争条件
由于表达式求值与线网更新事件的执行可能相互交织,因此可能出现竞争条件。例如:1
2
3
4
5
6assign p = q;
initial begin
q = 1;
#1 q = 0;
$display(p);
end
仿真器显示 1 或 0 都是正确的。将 q 赋值为 0 会触发 p 的更新事件。仿真器可以选择继续执行 $display 任务,也可以先执行 p 的更新,再执行 $display 任务。
语句调度
连续赋值语句
连续赋值语句对应一个对表达式中源元素敏感的过程。当表达式的值发生变化时,会使用当前值确定目标,将一个 active 更新事件添加到事件区域。连续赋值过程还会在零时刻被评估,以便传播常量值。这包括从端口连接推断出的隐式连续赋值。
过程连续赋值
过程连续赋值(即 assign 或 force 语句)对应一个对表达式中源元素敏感的过程。当表达式的值发生变化时,会使用当前值确定目标,将一个 active 更新事件添加到事件区域中。deassign 或 release 语句会解除任何对应的 assign 或 force 语句的激活状态。
阻塞赋值
带有赋值内延迟的阻塞赋值语句会使用当前值计算右侧表达式的值,然后使执行过程挂起,并安排为未来的事件。如果延迟为 0,该过程会被安排为当前时间的 Inactive 事件。如果从 Reactive 区域执行零延迟的阻塞赋值,该过程会被安排为 Re-Inactive 事件。
当过程恢复执行时(如果未指定延迟则立即恢复),过程会对左侧进行赋值,并基于左侧的更新触发任何相关事件。恢复执行时的值用于确定目标。随后,执行可以继续执行下一条顺序语句,或处理其他 Active 事件或 Reactive 事件。
非阻塞赋值
非阻塞赋值语句总是计算更新后的值,并将更新安排为 NBA 更新事件。如果延迟为零,则安排在当前时间步;如果延迟非零,则安排为未来事件。更新被放入事件区域时生效的值用于计算右侧值和左侧目标。
开关(晶体管)处理
(Todo)
端口连接
端口通过隐式的连续赋值语句或隐式的双向连接来连接进程。双向连接类似于两个网络之间始终启用的传输连接,但没有任何强度衰减。
端口始终可以表示为已声明的连接对象,具体如下:
- 如果是输入端口,则表示从外部表达式到本地(输入)网络或变量的连续赋值。
- 如果是输出端口,则表示从本地输出表达式到外部网络或变量的连续赋值。
- 如果是双向端口,则表示将本地网络与外部网络连接的非强度衰减晶体管。
原始终端(包括 UDP 终端)与模块端口不同。原始输出和双向终端应直接连接到1位网络或1位结构化网络表达式,中间没有任何可能改变强度的进程。原始评估产生的更改在连接的网络中作为主动更新事件进行调度。连接到1位网络或1位结构化网络表达式的输入终端也是直接连接的,中间没有任何可能影响强度的进程。连接到其他类型表达式的输入终端表示为从该表达式到与输入终端连接的隐式网络的隐式连续赋值。
子程序
子程序参数传递采用值传递方式,调用时传入值,返回时传出值。返回时的传出功能与任何阻塞赋值的行为方式相同。
PLI 回调控制点
(Todo)
第三章 词法约定
结构体字面量
结构字面量是结构赋值模式或具有常量成员表达式的模式表达式。结构字面量必须具有类型,该类型可以通过前缀显式指定,也可以通过类似赋值的上下文隐式指定。1
2
3typedef struct {int a; shortreal b;} ab;
ab c;
c = '{0, 0.0}; // 结构字面量的类型由左值上下文(c)确定
嵌套花括号应反映结构层次。例如:1
ab abarr[1:0] = '{'{1, 1.0}, '{2, 2.0}};
前例中类似C语言的替代写法 '{1, 1.0, 2, 2.0} 是不允许的。
结构字面量也可使用成员名与值组合,或采用数据类型与默认值形式:1
2
3c = '{a:0, b:0.0}; // 成员名称和对应的值
c = '{default:0}; // 所有元素的默认值设置为 0
d = ab'{int:1, shortreal:1.0}; // 使用成员类型设置默认值
在初始化结构体数组时,嵌套的花括号应反映数组和结构体的层次关系。例如:1
ab abarr[1:0] = '{'{1, 1.0}, '{2, 2.0}};
复制运算符可用于为精确数量的成员设置值,复制操作中的内层花括号将被移除。1
2
3
4
5struct {int X,Y,Z;} XYZ = '{3{1}};
typedef struct {int a,b[4];} ab_t;
int a,b,c;
ab_t v1[1:0] [2:0];
v1 = '{2{'{3{'{a,'{2{b,c}}}}}}};
数组字面量
数组字面量在语法上与C语言的初始化器相似,但允许使用复制运算符({{ }})。例如:1
int n[1:2][1:3] = '{'{0,1,2},'{3{4}}};
与C语言不同,花括号的嵌套必须遵循维度数量,但复制运算符可以嵌套。复制表达式中的内层花括号会被移除,且复制操作仅在一个维度内进行。例如:1
int n[1:2][1:6] = '{2{'{3{4, 5}}}};
等价于1
'{'{4,5,4,5,4,5},'{4,5,4,5,4,5}}
数组字面量是具有常量成员表达式的数组赋值模式或模式表达式。数组字面量必须具有类型,可以通过前缀显式指定,也可以通过类似赋值的上下文隐式指定。例如:1
2typedef int triple [1:3];
$mydisplay(triple'{0,1,2});
数组字面量还可以使用索引或类型作为键,并指定默认键值。例如:1
triple b = '{1:1, default:0}; // 索引2和3被赋值为0
第四章 基本数据类型
值集合
SystemVerilog的值集包含以下四种基本值:
- 0——表示逻辑零或假条件
- 1——表示逻辑一或真条件
- x——表示未知逻辑值
- z——表示高阻抗状态
注意:
- 当 z 值出现在门电路的输入端或在表达式中遇到时,其效果通常与 x 值相同。例外是金属氧化物半导体(MOS)原语,它可以传递 z 值。
- 这种基本数据类型的名称是 logic
- SystemVerilog 中的多种数据类型属于四值类型,能够存储全部四种逻辑值
- 四值向量的所有位均可独立设置为四种基本值之一
- 部分 SystemVerilog 数据类型为二值类型,其向量中的每个位只能存储 0 或 1 值
- 事件类型和实数类型不遵循该值集合
- 能够表示未知和高阻值的类型被称为四值类型,包括 logic、reg、integer 和 time
- 不具备未知值的类型则称为二值类型,例如 bit 和 int
- logic 与 reg 实际表示相同的数据类型
- 当四值类型自动转换为二值类型时,所有未知 x 或高阻态 z 比特位都将被转换为零
- DUT 应该使用四值类型构建,而 Testbench 通常使用二值类型(性能更好)
线网类型
- 线网类型可以表示结构实体(如门)之间的物理连接
- 线网本身不存储值(trireg 除外),其值由驱动源(如连续赋值或门)的值决定
- 若线网未连接任何驱动源,其值应为高阻态(z),除非该线网为 trireg 类型(此时线网将保持先前被驱动的值)
- 一个线网可以通过一个或多个连续赋值、原始输出或通过模块端口来写入
- 线网不能被过程赋值
- 当同一强度下的多个信号源在 wire 或 tri 上发生逻辑冲突时,将产生未知值(x)。
- 基础线网类型有如下子类型:
- wire/tri 发生冲突时的真值表如下:
变量类型
- 变量是数据存储元素的抽象表示。从一次赋值到下一次赋值之间,变量应持续存储其值。在程序中的赋值语句相当于触发器,它会改变数据存储元素中的数值。
- 变量可以通过一个或多个过程语句(包括过程连续赋值)来写入。最后一次写入决定其值。或者,变量也可以通过一个连续赋值或一个端口来写入。
- 变量可以是其他类型的紧凑或非紧凑联合体
- 对变量的独立元素进行的多次赋值将单独检查。独立元素包括结构的不同成员或数组的不同元素。紧凑类型中的每一位也是一个独立元素。因此,在紧凑类型的联合体中,联合体中的每一位都是一个独立元素。
- 左侧包含切片的赋值被视为对整个切片的单个赋值。因此,结构或数组可以有一个元素通过过程赋值,另一个元素通过连续赋值。并且结构或数组的元素可以通过多个连续赋值来赋值,前提是每个元素最多只被一个连续赋值覆盖。
- 在变量声明中设置静态变量的初始值(包括静态类成员)应在任何初始或始终过程开始之前完成
- 初始值不仅限于简单常量,还可包含运行时表达式,例如动态内存分配
基础数据类型
整数
| 名称 | 描述 |
|---|---|
| shortint | 2值类型,16比特有符号整数 |
| int | 2值类型,32比特有符号整数 |
| longint | 2值类型,64比特有符号整数 |
| byte | 2值类型,8比特有符号整数或ASCII字符 |
| bit | 2值类型,1比特无符号整数,可由用户定义向量大小 |
| logic | 4值类型,1比特无符号整数,可由用户定义向量大小 |
| reg | 4值类型,1比特无符号整数,可由用户定义向量大小 |
| integer | 4值类型,32比特有符号整数 |
| time | 4值类型,64比特无符号整数 |
- 整数类型使用整数运算,可分为有符号与无符号两种形式,这会影响到某些运算符的具体含义
- 数据类型 byte、shortint、int、integer 和 longint 默认为有符号类型;而数据类型 time、bit、reg 和 logic 及其数组类型则默认为无符号类型
- 可通过关键字 signed 和 unsigned 显式定义类型的符号属性
实数
- 实数类型包括 real、shortreal、realtime
- real 数据类型与 C 语言中的 double 类型相同。shortreal 数据类型与 C 语言中的 float 类型相同。- realtime 声明应被视为与 real 声明同义,并可互换使用
- 对实数及实数变量使用逻辑或关系运算符的结果为单比特标量值。并非所有运算符都可用于涉及实数及实数变量的表达式。
- 在以下情况下禁止使用实数常量与实数变量:
- 对实数变量应用边沿事件控制(posedge、negedge、edge)
- 对声明为 real 的变量进行位选或段选引用
- 向量的位选或段选引用中出现实数索引表达式
- 当实数赋值给整数时将发生隐式转换:
- 实数通过四舍五入转换为整数,而非直接截断
- 若实数的小数部分恰好为0.5,则采用向远离零的方向舍入规则
- 当表达式赋值给实数变量时也会发生隐式转换:
- 线网或变量中单个为x或z的比特位在转换时将被视为零
字符串(string)
字符串数据类型是一种有序的字符集合。
- 字符串类型的变量具有动态特性,其长度在仿真过程中可能发生变化
- 字符串变量的长度即该集合中字符的数量
- 通过对变量进行索引,可以选择字符串中的单个字符进行读取或写入操作
- 字符串变量中的单个字符属于字节类型(byte)
声明字符串变量的语法如下:1
string 变量名 [= 初始值];
其中变量名为有效标识符,可选的初始值可以是字符串字面量、表示空字符串的 "" 值,或字符串数据类型表达式。例如:1
2parameter string default_name = "John Smith";
string myName = default_name;
- 若声明时未指定初始值,变量将被初始化为空字符串
""。空字符串的长度为零。 - 字符串变量的索引应从 0 到 N-1 编号(其中 N 为字符串长度),索引 0 对应字符串的第一个(最左侧)字符,索引 N-1 对应最后一个(最右侧)字符。
- 字符串变量可以取特殊值
"",即空字符串。对空字符串变量进行索引访问属于越界访问。 - 字符串变量不得包含特殊字符
\0。若将值 0 赋值给字符串中的字符,该操作将被忽略。
字符串字面量转换
- 当字符串字面量被赋值给字符串类型变量,或在涉及字符串类型操作数的表达式中使用时,会隐式转换为字符串类型。字符串长度可以任意,且不会发生截断。
- 当将字符串字面量赋值给不同大小的整型变量紧凑数组时,会根据需要对字面量进行截断(从左侧开始)或在左侧补零。
- 当字符串字面量赋值给整型数据类型变量时,若数据对象的位数不等于字符串字面量字符数乘以 8,则字面量会右对齐,并根据需要在左侧截断或补零。例如:
1
2
3byte c = "A"; // c = "A"
bit [10:0] b = "\x41"; // b = 'b000_0100_0001
bit [1:4][7:0] h = "hello" ; // h = "ello" - 将整型值转换为字符串变量时,该变量会相应扩展或收缩以容纳该整型值。如果整型值的位数不是8的倍数,则在其左侧填充零,使其位数成为8的倍数。
将字符串字面量赋值给字符串变量时,按以下步骤进行转换:
- 字符串字面量中的所有
\0字符将被忽略(即从字符串中移除)。 - 如果第一步的结果是空字符串字面量,则字符串被赋值为空字符串。
- 否则,字符串被赋值为字符串字面量中剩余的字符。
将整型值转换为字符串变量时,按以下步骤进行:
- 如果整数值的位宽不是 8 的倍数,则将该整数值向左扩展并用零填充,直到其位宽为 8 的倍数。扩展后的值将被视为字符串字面量,其中每连续的 8 位代表一个字符。
- 随后,将之前描述的字符串字面量转换步骤应用于该扩展值。
1 | |
操作符
SystemVerilog提供了一组可用于操作字符串变量和字符串字面量组合的运算符。
| 操作 | 含义 |
|---|---|
Str1 == Str2 |
相等性。检查两个字符串操作数是否相等。若相等则结果为 1,若不相等则结果为 0。两个操作数均可为字符串类型的表达式,或者其中一个为字符串类型的表达式,另一个为字符串字面量(在比较时会隐式转换为字符串类型)。若两个操作数均为字符串字面量,则该运算符与整型类型的相等性运算符相同。 |
Str1 != Str2 |
不等性。== 的逻辑否定 |
Str1 < Str2Str1 <= Str2Str1 > Str2Str1 >= Str2 |
比较:关系运算符在对应条件为真时返回 1,该条件基于字符串 Str1 和 Str2 的字典序进行比较。比较过程使用字符串的 compare 方法实现。两个操作数可以是字符串类型的表达式,或者其中一个是字符串类型表达式而另一个是字符串字面量(后者将在比较时隐式转换为字符串类型)。若两个操作数均为字符串字面量,则该运算符与整型数据使用的比较运算符相同。 |
{Str1,Str2,...,Strn} |
连接:每个操作数可以是字符串字面量或字符串类型的表达式。如果所有操作数都是字符串字面量,则该表达式表现为整数值的连接;若此类连接的结果被用于涉及字符串类型的表达式中,则隐式转换为字符串类型。如果至少有一个操作数是字符串类型的表达式,则在执行连接之前,所有字符串字面量操作数都转换为字符串类型,且连接结果为字符串类型。 |
{multiplier{Str}} |
复制:Str 可以是字符串字面量或字符串类型的表达式。乘数为整数类型的表达式,且不要求是常量表达式。若乘数为非常量或 Str 是字符串类型的表达式,则结果为包含 N 个 Str 连接副本的字符串,其中 N 由乘数指定。若 Str 是字面量且乘数为常量,则该表达式行为类似于数值复制(若结果用于涉及字符串类型的其他表达式中,则会隐式转换为字符串类型)。 |
Str[index] |
索引:返回一个字节,即给定索引处的 ASCII 码。索引范围从 0 到 N-1,其中 N 是字符串中的字符数。如果给定的索引超出范围,则返回 0。在语义上等同于 Str.getc(index)。 |
Str.method(...) |
点运算符用于在字符串上调用指定的方法。 |
内置成员函数
str.len()返回字符串的长度,即字符串中的字符数。1
function int len();如果 str 是空字符串
"",则str.len()返回 0。str.putc(i, c)将字符串 str 中的第 i 个字符替换为给定的整数值。1
function void putc(int i, byte c);- putc 不会改变 str 的大小:如果
i < 0或i >= str.len(),则 str 保持不变。 - 如果 putc 的第二个参数为零,则字符串不受影响。
putc 方法赋值
str.putc(i, c)在语义上等价于str[i] = c。str.getc(i)返回字符串 str 中第 i 个字符的 ASCII 码。1
function byte getc(int i);- 如果
i < 0或i >= str.len(),则str.getc(i)返回 0。 getc 方法赋值
c = str.getc(i)在语义上等价于c = str[i]。str.toupper()和str.tolower()返回一个字符串,其中 str 中的字符被转换为大写/小写。1
2function string toupper();
function string tolower();str 保持不变。
str.compare(s)比较 str 和 s,类似于 ANSI C 的 strcmp 函数,涉及词法顺序和返回值。1
function int compare(string s);str.icompare(s)比较 str 和 s,类似于 ANSI C 的 strcmp 函数,涉及词法顺序和返回值,但比较不区分大小写。1
function int icompare(string s);str.substr(i, j)返回一个新的字符串,该字符串是由 str 中位置 i 到 j 的字符组成的子串。1
function string substr(int i, int j);如果
i < 0、j < i或j >= str.len(),substr() 返回""(空字符串)。str.atoi()/str.atohex()/str.atooct()/str.atobin()将 str 转换成十进制,str 使用不同的进制表示1
2
3
4function integer atoi();
function integer atohex();
function integer atooct();
function integer atobin();- atoi 将字符串解释为十进制。
- atohex 将字符串解释为十六进制。
- atooct 将字符串解释为八进制。
- atobin 将字符串解释为二进制。
- 转换过程会扫描所有前导数字和下划线字符(
_),并在遇到任何其他字符或字符串结尾时立即停止。如果未遇到任何数字,则返回零。它不会解析整数字面量的完整语法(符号、大小、撇号、基数)。 - 这些转换函数返回一个 32 位整数值。可能会发生截断且不发出警告
1 | |
str.atoreal()返回与 str 中 ASCII 十进制表示对应的实数。1
function real atoreal();转换过程会解析实数常量。一旦遇到任何不符合此语法的字符或字符串结尾,扫描立即停止。如果未遇到任何数字,则返回零。
str.itoa(i)/str.hextoa(i)/str.octtoa(i)/str.bintoa(i)将 i 的 ASCII 十进制/十六进制/八进制/二进制表示存储到 str 中(atoi/atohex/atooct/atobin 的逆操作)。1
2
3
4function void itoa(integer i);
function void hextoa(integer i);
function void octtoa(integer i);
function void bintoa(integer i);str.realtoa(r)将 r 的 ASCII 实数表示存储到 str 中(atoreal 的逆操作)。1
function void realtoa(real r);
事件(event)
- 事件数据类型为同步对象提供了一个句柄
- 事件变量所引用的对象可以被显式触发和等待
- 事件变量具有持久触发状态,该状态在整个时间步长内持续存在
- 事件变量可以被赋值或与另一个事件变量进行比较,或者被赋予特殊值 null
- 当被赋值为另一个事件变量时,两个事件变量引用同一个同步对象
- 当被赋值为 null 时,同步对象与事件变量之间的关联将被断开
- 如果在事件变量的声明中未指定初始值,则该变量将被初始化为一个新的同步对象。
枚举(enum)
定义方法
- 枚举类型声明了一组整型命名常量
- 若未声明数据类型,默认数据类型应为 int(二值)
- 对于没有显式数据类型或显式二值声明的枚举类型,若其枚举名称中包含 x 或 z 赋值,则视为语法错误
1
2// 语法错误示例:IDLE=2'b00, XX=2'bx <错误>, S1=2'b01, S2=2'b10
enum bit [1:0] {IDLE, XX='x, S1=2'b01, S2=2'b10} state, next; - 对于四值类型(如 integer)的枚举声明,若其中包含一个或多个带有 x 或 z 赋值的枚举名称,则是允许的
1
2// 正确示例:IDLE=0, XX='x, S1=1, S2=2
enum integer {IDLE, XX='x, S1='b01, S2='b10} state, next; - 若在带有 x 或 z 赋值的枚举名称后出现未赋值的枚举名称,则视为语法错误
1
2// 语法错误示例:IDLE=0, XX='x, S1=??, S2=??
enum integer {IDLE, XX='x, S1, S2} state, next; - enum 值可以转换为整数类型,并从初始值 0 开始递增。可以为部分枚举名称设置具体值,而其他名称可不设置。未显式赋值的名称会自动分配为前一个名称值的递增结果。若自动递增导致超过枚举类型可表示的最大值,则会产生错误。
1
enum {bronze=3, silver, gold} medal; // silver=4, gold=5 - 枚举名称及其对应的整数值都必须唯一。若将两个值赋予同一名称,或将同一值赋予两个名称(无论该值是显式设置还是通过自动递增产生),均会导致错误。
1
2// 错误:c 和 d 均被赋值为8
enum {a=0, b=7, c, d=8} alphabet; - 若首个名称未显式赋值,则其默认初始值为0
1
2// a=0, b=7, c=8
enum {a, b=7, c} alphabet; - 整数值表达式会被转换为枚举基类型,超出范围视为错误;对于无符号基类型,若转换截断数值且被丢弃的任何位非零,则发生错误;对于有符号基类型,若转换截断数值且被丢弃的任何位不等于结果的符号位,则发生错误;若整数值表达式为有尺寸的字面常量,即使其值在可表示范围内,只要尺寸与枚举基类型不同即视为错误;转换后的值将用于枚举名称的赋值,包括唯一性检查和为后续名称自动递增取值。
1
2
3
4
5
6
7
8// 正确声明 - bronze和gold未指定尺寸
enum bit [3:0] {bronze='h3, silver, gold='h5} medal2;
// 正确声明 - bronze和gold的尺寸声明是冗余的
enum bit [3:0] {bronze=4'h3, silver, gold=4'h5} medal3;
// bronze和gold成员声明错误
enum bit [3:0] {bronze=5'h13, silver, gold=3'h5} medal4;
// c声明错误,至少需要2位
enum bit [0:0] {a,b,c} alphabet;
类型转换
- 枚举类型是强类型。除非使用显式类型转换,或者该枚举变量是联合体(union)的成员,否则不能直接将枚举集合之外的值赋给枚举类型的变量。
- 枚举值仍可在表达式中用作常量,并且其结果可以赋给任何兼容的整型变量
- 枚举变量会自动转换为整数值,但将任意表达式赋给枚举变量则需要显式类型转换
- 在表达式中使用的枚举变量或标识符会自动转换为枚举声明的基础类型
- 转换为枚举类型会导致表达式被转换为其基础类型,而不会检查值的有效性
1 | |
批量声明
使用下表中的语法,一系列枚举元素可以自动生成。
| 语法 | 含义 |
|---|---|
name |
将下一个连续数字与名称关联 |
name = C |
将常量 C 与名称关联 |
name[N] |
生成序列中的 N 个命名常量:name0, name1,…, nameN–1(N 应为正整数) |
name[N] = C |
可选地,可以为生成的命名常量分配一个常量,以将该常量与第一个生成的命名常量关联;后续生成的命名常量则关联连续值(N 应为正整数) |
name[N:M] |
创建一个从命名常量 nameN 开始递增或递减,直至达到命名常量 nameM 的序列(N 和 M 应为非负整数) |
name[N:M] = C |
可选地,可以为生成的命名常量分配一个常数值,以便将该常量与第一个生成的命名常量关联;后续生成的命名常量将依次关联连续的值(N 和 M 应为非负整数) |
1 | |
内置成员函数
SystemVerilog 包含一组专门用于遍历枚举类型值的方法:
first()方法返回枚举的第一个成员的值。1
function enum first();last()方法返回枚举的最后一个成员的值。1
function enum last();next()方法从给定变量的当前值开始,返回第 N 个后续枚举值(默认为下一个值)。当到达枚举的末尾时,会回绕到枚举的开头。如果给定值不是枚举的成员,next()方法将返回枚举的默认初始值。1
function enum next( int unsigned N = 1 );prev()方法从给定变量的当前值开始,返回第 N 个前驱枚举值(默认为前一个值)。当到达枚举的开头时,会回绕到枚举的末尾。如果给定值不是枚举的成员,prev()方法将返回枚举的默认初始值。1
function enum prev( int unsigned N = 1 );num()方法返回给定枚举中的元素数量。1
function int num();name()方法返回给定枚举值的字符串表示形式。如果给定值不是该枚举的成员,则name()方法返回空字符串。1
function string name();
向量定义
声明为 reg、logic 或 bit 的数据对象,若未指定范围,则视为 1 位宽,称为标量。通过指定范围声明的此类多位数对象称为向量。向量是标量的紧凑数组。
- 范围指定的语法为
[msb : lsb] - 最高有效位由 msb 常数表达式指定,位于范围的左侧值
- 最低有效位由 lsb 常数表达式指定,位于范围的右侧值
- msb 常数表达式和 lsb 常数表达式都必须是常量整数表达式,表达式值可以是正数、负数或零
- msb 和 lsb 中若包含任何未知(x)或高阻态位,则视为非法
- lsb值可以大于、等于或小于msb值。
- reg、logic 和 bit 类型的向量默认是无符号量,除非被声明为有符号类型,或连接到声明为有符号的端口
类型兼容性
- 某些结构和操作要求其操作数具备一定程度的类型兼容性才能合法执行
- 定义了五种类型兼容级别:匹配、等价、赋值兼容、强制转换兼容以及非等价
- 数据类型标识符的作用域应包含层次实例作用域。换言之,每个在实例内部声明了用户自定义类型的实例都会创建一个独特的类型。若要在同一模块、接口、程序或检查器的多个实例之间实现类型匹配或等价,类、枚举、非紧凑结构体或非紧凑联合体类型必须在编译单元作用域中声明于模块、接口、程序或检查器的声明之上,或从包中导入。对于类型匹配而言,即使是紧凑结构体和紧凑联合体类型也需遵循此规则。
匹配类型
通过以下归纳定义将两种数据类型定义为匹配的数据类型。若两种数据类型不符合以下定义,则应将其定义为不匹配。
- 任何内置类型在其所有作用域内均与自身的其他出现形式匹配。
- 在类型标识符的作用域内,重命名内置类型或用户定义类型的简单 typedef 或类型参数覆盖与该内置类型或用户定义类型匹配。
1
2typedef bit node; // 'bit' 和 'node' 是匹配的
typedef type1 type2; // 'type1' 是 'type2' 是匹配的 - 匿名枚举、结构体或联合类型仅与在同一声明语句中声明的数据对象自身匹配,而不与其他任何数据类型匹配。
1
2struct packed {int A; int B;} AB1, AB2; // AB1, AB2 匹配
struct packed {int A; int B;} AB3; // AB3 与 AB1 不匹配 - 枚举、结构体、联合体或类的 typedef 类型声明,在数据类型标识符的作用域内匹配自身以及使用该数据类型声明的数据对象类型。
1
2
3
4typedef struct packed {int A; int B;} AB_t;
AB_t AB1; AB_t AB2; // AB1 和 AB2 匹配
typedef struct packed {int A; int B;} otherAB_t;
otherAB_t AB3; // AB3 不和 AB1/AB2 匹配 - 一种没有预定义宽度的简单位向量类型与一种有预定义宽度的简单位向量类型,如果两者都是二值或都是四值,都是有符号或都是无符号,具有相同的宽度,并且没有预定义宽度的简单位向量类型的范围是[宽度-1:0],则它们匹配。
1
2typedef bit signed [7:0] BYTE; // 与 byte 类型匹配
typedef bit signed [0:7] ETYB; // 与 byte 类型不匹配 - 如果两个数组类型均为紧凑数组或均为非紧凑数组,属于同一种数组类型(固定尺寸数组、动态数组、关联数组或队列),具有匹配的索引类型(针对关联数组)以及匹配的元素类型,则这两个数组类型相匹配。固定尺寸数组还应具有相同的左右范围边界。请注意,多维数组的元素类型本身也是数组类型。
1
2
3
4
5
6typedef byte MEM_BYTES [256];
typedef bit signed [7:0] MY_MEM_BYTES [256]; // MY_MEM_BYTES 和 MEM_BYTES 匹配
typedef logic [1:0] [3:0] NIBBLES;
typedef logic [7:0] MY_BYTE; // MY_BYTE 和 NIBBLES 不匹配
typedef logic MD_ARY [][2:0];
typedef logic MD_ARY_TOO [][0:2]; // 不匹配 MD_ARY - 在类型上显式添加有符号或无符号修饰符,若未改变其默认的符号属性,则创建的类型将与未显式指定符号的类型相匹配。
1
typedef byte signed MY_CHAR; // MY_CHAR 与 byte 类型完全匹配 - 对于在包中声明的枚举、结构体、联合体或类类型,无论该类型被导入到哪个作用域,其 typedef 定义始终与自身类型保持一致。
等效类型
使用以下归纳定义将两种数据类型定义为等效数据类型。若两种数据类型未通过以下定义被定义为等效,则应将其定义为非等效。
- 若两种类型匹配,则它们等效。
- 匿名枚举、非紧凑结构体或非紧凑联合类型在同一声明语句内声明的数据对象中仅与自身等效,且不与其他任何数据类型等效。
1
2struct {int A; int B;} AB1, AB2; // AB1、AB2 是等效类型
struct {int A; int B;} AB3; // AB3 与 AB1 类型不等效 - 紧凑数组、紧凑结构体、紧凑联合体以及内置整数类型在以下条件下是等效的:它们包含相同的总位数,全部为二值或全部为四值,且全部为有符号或全部为无符号。(如果紧凑结构体或联合体中任意位为四值,则整个结构体或联合体被视为四值)
1
2typedef bit signed [7:0] BYTE; // 等效于 byte 类型
typedef struct packed signed {bit[3:0] a, b;} uint8; // 等效于 bytes 类型 - 非紧凑的固定大小数组类型,若其元素类型等价且尺寸相等,则视为等价类型;实际的范围边界可以不同。需要注意的是,多维数组的元素类型本身也是数组类型。
1
2
3
4
5bit [9:0] A [0:5];
bit [1:10] B [6];
typedef bit [10:1] uint10;
uint10 C [6:1]; // A、B 和 C 具有等价类型
typedef int anint [0:0]; // anint 与 int 类型不等价 - 动态数组、关联数组和队列类型,若属于同一种数组类型(动态、关联或队列),具有等价的索引类型(针对关联数组),且具有等价的元素类型,则视为等价类型。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26package p1;
typedef struct {int A;} t_1;
endpackage
typedef struct {int A;} t_2;
module sub();
import p1::t_1;
parameter type t_3 = int;
parameter type t_4 = int;
typedef struct {int A;} t_5;
t_1 v1; t_2 v2; t_3 v3; t_4 v4; t_5 v5;
endmodule
module top();
typedef struct {int A;} t_6;
sub #(.t_3(t_6)) s1 ();
sub #(.t_3(t_6)) s2 ();
initial begin
s1.v1 = s2.v1; // 合法,两个类型都是从 p1 中来的
s1.v2 = s2.v2; // 合法,两个类型都是从 $unit 中来的
s1.v3 = s2.v3; // 合法,两个类型都是从 top 中来的
s1.v4 = s2.v4; // 合法,两个类型都是 int
s1.v5 = s2.v5; // 不合法,两个类型分别从 s1 和 s2 中来
end
endmodule
赋值兼容性
所有等效类型,以及所有定义了隐式转换规则的非等效类型,都属于赋值兼容类型
- 所有整数类型都是赋值兼容的
- 赋值兼容类型之间的转换可能因截断或舍入而导致数据丢失
- 非紧凑数组与某些其他非等效类型的数组也具有赋值兼容性
- 兼容性可以是单向的。例如,枚举类型无需显式转换即可转换为整数类型,但反之则不行
- 所有赋值兼容类型,以及所有定义了显式转换规则的非等价类型,都属于强制转换兼容类型
- 类型不兼容包括所有剩余的、没有定义隐式或显式转换规则的非等价类型。类句柄、接口类句柄以及通道句柄与所有其他类型均存在类型不兼容性。
强制类型转换
数据类型可以通过使用强制转换(')操作来改变。
静态类型转换
在静态类型转换中,待转换的表达式应置于圆括号内,括号前需标注转换类型及撇号。
- 若表达式与转换类型具有赋值兼容性,则转换结果应等同于将表达式赋值给该类型变量后所获得的值。
若表达式与转换类型不具赋值兼容性,则当转换类型为枚举类型时,其行为应符合相关规定;当转换类型为位流类型时,其行为应符合相关规定。
1
2int'(2.0 * 3.0)
shortint'({8'hFA,8'hCE})若表达式 expr_1 和 expr_2 分别与数据类型 cast_t1 和 cast_t2 具有赋值兼容性,则:
1
A = cast_t1'(expr_1) + cast_t2'(expr_2);等价于:
1
2
3
4
5cast_t1 temp1;
cast_t2 temp2;
temp1 = expr_1;
temp2 = expr_2;
A = temp1 + temp2;由此可见,若隐式类型转换(如
temp1 = expr1)有定义,其转换结果与对应的显式类型转换(cast_t1'(expr1))相同。若转换类型是具有正整数值的常量表达式,则括号内的表达式应按指定长度进行填充或截断。若指定长度为零或负数,则应视为错误。
- 符号性也可以被改变。
signed'(x)在改变大小或符号时,强制类型转换内的表达式应为整数值。 - 改变大小时,强制类型转换应返回一个具有单一
[n-1:0]维度的紧凑数组类型在赋值该表达式后所持有的值,其中 n 是转换后的大小。符号性应保持不变,即结果的符号性应为转换内表达式的自确定有符号性。如果转换内的表达式是二态类型,数组元素应为 bit 类型;否则应为 logic 类型。 - 改变符号时,强制类型转换应返回一个具有单一
[n-1:0]维度的紧凑数组类型在赋值该表达式后所持有的值,其中 n 是要转换的表达式的位数($bits(expression))。结果的符号性应为转换类型所指定的符号性。如果转换内的表达式是二态类型,数组元素应为 bit 类型;否则应为 logic 类型。 $signed()和$unsigned()系统函数分别返回与signed'()和unsigned'()相同的结果。1
2
3
4logic [7:0] regA;
logic signed [7:0] regS;
regA = unsigned'(-4); // regA = 8'b11111100
regS = signed'(4'b1100); // regS = -4
表达式可以通过常量强制类型转换变为常量。1
const'(x)
将表达式强制类型转换为常量时,要转换的表达式的类型应保持不变。唯一的效果是将该值视为已用于定义该表达式类型的 const 变量。
当使用强制类型转换或赋值将 shortreal 转换为 int 或 32 位时,其值会被舍入。因此,转换可能会丢失信息。要将 shortreal 转换为其底层位表示而不丢失信息,需要使用 $shortrealtobits。要将 shortreal 值的位表示转换回 shortreal,需要使用 $bitstoshortreal。
结构体可以转换为保留位模式的位表示。换句话说,它们可以无损地转换回相同的值。当非紧凑数据转换为紧凑表示时,紧凑表示中的数据顺序使得结构体中的第一个字段占据最高有效位。其效果等同于按顺序连接数据项(结构体字段或数组元素)。非紧凑结构体或数组中的元素类型必须对紧凑表示有效,才能强制类型转换为任何其他类型(无论是紧凑还是非紧凑)。
紧凑类型之间的显式强制类型转换不是必需的,因为它们会隐式转换为整数值,但工具可以使用强制类型转换来执行更强的类型检查。
动态类型转换
(Todo)
流类型转换
(Todo)
用户自定义类型
SystemVerilog 的数据类型可以通过 typedef 扩展为用户自定义类型。常用的声明用户自定义类型的语法有三种:
typedef data_type type_identifier { variable_dimension } ;typedef [ enum | struct | union | class | interface class ] type_identifier ;(基于接口的类型定义)typedef interface_instance_identifier constant_bit_select . type_identifier type_identifier ;(前向类型定义)在类型转换中,对于复杂数据类型必须使用用户自定义的数据类型名称,因为该操作仅允许简单数据类型名称
- 当使用非紧凑数组类型时,用户自定义类型名称也需作为类型参数值使用
- 类型参数还可用于声明类型标识符。用户自定义数据类型的声明必须早于对其类型标识符的任何引用。
- 用户自定义数据类型标识符的作用域规则与数据标识符相同,但禁止对类型标识符进行层次化引用。
- 通过端口引用接口内部定义的类型标识符不属于层次化引用,只要在使用前进行本地重定义即可允许。此类类型定义称为基于接口的类型定义。
有时,用户自定义类型需要在类型内容被定义之前进行声明。这对于从基本数据类型派生的用户自定义类型非常有用:枚举(enum)、结构体(struct)、联合体(union)、接口类(interface class)以及类(class)。为支持此功能,提供了以下形式的前向类型定义(forward typedef):
typedef enum type_identifier;typedef struct type_identifier;typedef union type_identifier;typedef class type_identifier;typedef interface class type_identifier;typedef type_identifier;虽然空用户自定义类型声明可用于类的耦合定义,但它不能用于结构体的耦合定义,因为结构体是静态声明的,且不支持结构体句柄。
- 用户自定义类型的基本数据类型无需在前向声明中定义。前向类型定义声明的实际数据类型必须在同一局部作用域或生成块内解析。如果 type_identifier 未解析为数据类型,则视为错误。如果前向类型声明指定了基本数据类型,而实际类型定义不符合该基本数据类型,则同样视为错误。在同一作用域内,前向类型声明可以出现在最终类型定义之前或之后,这是合法的。同一作用域内允许对同一类型标识符进行多次前向类型声明。术语“前向类型声明”的使用并不要求前向声明必须位于最终类型定义之前。
- 在最终类型定义之前,前向类型定义应被视为不完整的。虽然不完整的前向类型、类型参数以及基于接口的类型定义可能解析为类类型,但使用类作用域解析运算符选择以此类前缀命名的类型时,应仅限于类型定义声明。如果前缀未解析为类,则视为错误。
示例:1
2
3
4
5
6
7typedef C;
C::T x; // 非法:C是不完整的前向类型
typedef C::T c_t; // 合法:通过typedef引用C::T
c_t y;
class C;
typedef int T;
endclass
第五章 聚合数据类型
结构体(Structure)
非紧凑结构体(unpacked structure)
结构体代表一组数据类型的集合,既可以作为一个整体被引用,也可以通过名称单独引用构成该结构体的各个数据类型
- 默认情况下,结构体是非紧凑存储的
- 非紧凑结构体可以包含任意数据类型
- 非紧凑结构体无法被当作整体参与运算,也就无法定义有符号或无符号
1
2
3
4
5
6
7struct { bit [7:0] opcode; bit [23:0] addr; } IR; // 匿名结构体及其实例 IR
IR.opcode = 1; // 设置 IR 的字段值
typedef struct {
bit [7:0] opcode;
bit [23:0] addr;
} instruction; // 命名结构体类型
instruction IR; // 定义变量
紧凑结构体(packed structure)
紧凑结构体是一种将向量细分为子字段的机制,这些子字段可以像成员一样方便地访问
- 紧凑结构由位字段组成,这些位字段在内存中紧密排列,没有间隙
- 紧凑结构与非紧凑结构的区别在于,当紧凑结构作为主对象出现时,它被视为单个向量
- 紧凑结构也可以作为一个整体用于算术和逻辑运算,其行为由其有符号性决定,默认为无符号
- 指定的第一个成员是最高有效位,后续成员按重要性递减排列
- 在紧凑结构中,仅允许使用紧凑数据类型以及整数数据类型
- 如果紧凑结构中的所有数据类型都是二值类型,则该结构整体被视为一个二值向量
- 如果紧凑结构中的任何数据类型是四值类型,则该结构整体被视为一个四值向量
- 如果结构中同时存在二值成员,读取这些成员时会存在从四值到二值的隐式转换,写入时则存在从二值到四值的隐式转换
- 可以像处理范围[n-1:0]的紧凑数组那样选择紧凑结构中的一个或多个位
1
2
3
4
5
6
7
8
9
10
11
12struct packed signed {
int a;
shortint b;
byte c;
bit [7:0] d;
} pack1; // signed, 2-state
struct packed unsigned {
time a;
integer b;
logic [31:0] c;
} pack2; // unsigned, 4-state
联合体(Union)
联合体表示可通过其命名成员数据类型之一访问的单一存储单元
- 每次只能使用联合体中的一种数据类型
- 默认情况下,联合体是非紧凑的
- 成员类型的大小任意,不必相同
- 动态类型和 chandle 类型仅能在带标签的联合体(tagged union)中使用
1 | |
- 若未在非紧凑联合类型变量的声明中指定初始值,则该变量应初始化为联合类型声明顺序中第一个成员类型的默认初始值
- 为简化非紧凑联合的使用,存在一项特殊规定:若一个非紧凑联合包含多个共享相同初始序列的非紧凑结构体,且当前该非紧凑联合对象包含其中任一结构体,则允许在联合完整类型声明可见的任何位置检查这些结构体的公共初始部分。当两个结构体前一个或多个初始成员对应的类型相同时,即被视为共享相同初始序列。
紧凑联合体
- 紧凑联合体仅能包含整型数据类型的成员
- 一个紧凑的、无标签的联合体的所有成员必须具有相同的大小
- 写入某个联合体成员,可以从另一个成员读回对应的值
- 当紧凑联合体作为主表达式出现时,它应被视为单个向量
- 紧凑联合体也可以作为一个整体用于算术和逻辑运算符,其行为由其符号性决定,默认情况下为无符号
- 紧凑联合体的一个或多个位可以被选择,就好像它是一个范围为[n-1:0]的紧凑数组一样。
- 只有紧凑数据类型和整数数据类型才可以在紧凑联合体中使用
- 如果紧凑联合体包含一个二值成员和一个四值成员,则整个联合体为四值
- 在读取时存在从四值到二值的隐式转换,在写入二值成员时存在从二值到四值的隐式转换。
标记联合体
(Todo)
数组(Array)
SystemVerilog 支持数据的紧凑数组和非紧凑数组
- “紧凑数组”用于指在数据标识符名称之前声明的维度
- “非紧凑数组”则用于指在数据标识符名称之后声明的维度
1
2bit [7:0] c1; // 标量位类型的紧凑数组
real u [7:0]; // 实数类型的非紧凑数组 - 一维紧凑数组通常被称为向量
- SystemVerilog 也允许多维紧凑数组的存在(注意:Verilog 不允许)
- 非紧凑数组可以是固定大小的数组、动态数组、关联数组或队列
- 非紧凑数组可以由任何数据类型构成,包括其他紧凑或非紧凑数组
紧凑数组(packed array)
紧凑数组是一种将向量细分为子字段的机制,这些子字段可以像数组元素一样方便地访问
- 紧凑数组保证以连续的位集合形式表示
- 当紧凑数组作为主操作数出现时,它被视为单个向量
- 如果紧凑数组被声明为有符号类型,则将其视为单个向量时应当是有符号的
- 数组的各个元素默认是无符号的,除非它们属于已声明为有符号的命名类型
- 对紧凑数组进行部分选择操作时,结果始终为无符号类型
- 紧凑数组支持任意长度的整数类型
- 紧凑数组只能由单比特数据类型(bit、logic、reg)、枚举类型,以及递归嵌套的其他紧凑数组和紧凑结构构成
- 具有预定义宽度的整数类型不应声明为紧凑数组维度(包括 byte、shortint、int、longint、integer 和 time),但它与单维度 [n-1:0] 的紧凑数组类型相匹配,并且可以像紧凑数组一样进行选择
1
2byte c2; // 等同于 bit signed [7:0] c2;
integer i1; // 等同于 logic signed [31:0] i1; - 紧凑数组的初始化可以使用连接运算
非紧凑数组(unpacked array)
- 非紧凑数组可以由任何数据类型构成
- 其元素本身为数组的数组被声明为多维数组
- 非紧凑数组应在声明标识符后通过指定元素地址范围来声明
- 线网数组的元素可以像标量或向量线网一样使用
- 每个固定大小的维度应由一个地址范围表示,例如[1:1024],或使用单个正数来指定固定大小非紧凑数组的尺寸,类似于C语言(换言之,[size]等同于[0:size-1])(Verilog不允许这样的语法)
- 指定地址范围的表达式必须是常量整数表达式(正整数、负整数或零)
数组操作
以下操作适用于所有数组,无论是紧凑数组还是非紧凑数组。这些规则所附的示例假设 A 和 B 是具有相同形状和类型的数组。
- 读取和写入数组,例如:
A = B - 读取和写入数组的切片,例如:
A[i:j] = B[i:j] - 读取和写入数组的可变切片,例如:
A[x +: c] = B[y +: c] - 读取和写入数组的元素,例如:
A[i] = B[i] - 对数组或数组切片进行相等性操作,例如:
A==B, A[i:j] != B[i:j]
以下操作仅适用于紧凑数组,不适用于非紧凑数组。这些规则所附的示例假设 A 是一个数组。
- 从整数赋值,例如:
A = 8'b11111111; - 在表达式中被视为整数,例如:
(A + 3)
如果非紧凑数组被声明为有符号类型,则这仅适用于数组的各个元素,因为整个数组无法被视为单个向量。
多维数组
多维数组是由数组构成的数组。多维数组可以通过在单个声明中包含多个维度来声明。标识符前的维度设置的是紧凑维度,而标识符后的维度设置的是非紧凑维度。1
2
3// 10 个元素,每个元素由 4 个 8 位字节组成
// 即每个元素打包为 32 位,注意不是 4+8=12 位
bit [3:0] [7:0] joe [1:10];
可以按如下方式使用:1
2joe[9] = joe[8] + 1; // 4字节加法
joe[7][3:2] = joe[6][1:0]; // 2字节复制
- 在多维声明中,类型之后、名称之前的维度比名称之后的维度变化更快
- 在维度列表中,最右侧的维度变化最快。
- 在引用时,紧凑维度位于非紧凑维度之后
位选和切片
表达式可以选择紧凑数组的一部分,或任何整数类型的一部分(默认从0开始向下编号)。
- 术语“位选”指从单维度紧凑数组中选取一个或多个连续位。例如:
1
2
3logic [63:0] data;
logic [7:0] byte2;
byte2 = data[23:16]; // 从data中选取8位的部分 - 术语“切片”指从数组中选取一个或多个连续元素。例如:
1
2
3bit [3:0] [7:0] j; // j为紧凑数组
byte k;
k = j[2]; // 从j中选取单个8位元素 - 一个或多个连续元素可通过切片选取。紧凑数组的切片仍是紧凑数组,非紧凑数组的切片仍是非紧凑数组。例如:
1
2
3bit signed [31:0] busA [7:0]; // 包含8个32位向量的非紧凑数组
int busB [1:0]; // 包含2个整数的非紧凑数组
busB = busA[7:6]; // 从busA中选取2个向量的切片 - 位选或切片的大小必须是常量,但其位置可以是变量。例如:
1
2
3int i = bitvec[j +: k]; // k必须为常量
int a[x:y], b[y:z], e;
a = {b[c -: d], e}; // d必须为常量 - 数组切片仅能应用于一个维度,但表达式中其他维度可包含单索引值
无效索引
- 如果索引表达式超出范围,或者索引表达式中存在任何位为 x 或 z,则该索引无效
- 从任何类型的非紧凑数组、关联数组中读取无效索引时,将返回下表中指定的值
| array 元素类型 | 读取到的值 |
|---|---|
| 四值整数类型 | 'X |
| 二值整数类型 | '0 |
| 枚举类型 | 本表格中对应枚举基础类型的值 |
| real, shortreal | 0.0 |
| string | "" |
| class | null |
| interface class | null |
| event | null |
| chandle | null |
| virtual interface | null |
| 可变非紧凑数组(动态数组、队列、关联数组) | 空数组 |
| 固定非紧凑数组 | 一个数组,其所有元素的值均符合本表中该数组元素类型所指定的值 |
| 非紧凑数组结构体 | 一个结构体,其每个成员的值均为此表中为该成员类型所指定的值,除非该成员在声明时已包含初始赋值,此时该成员的值应为其初始赋值所给定的值。 |
| 非紧凑数组联合体 | 在此表中为联合体第一个成员的类型指定的值 |
- 向数组写入无效索引时,不会执行任何操作,但以下两种情况除外:
- 写入队列的
[$+1]元素 - 创建关联数组的新元素
- 写入队列的
动态数组(dynamic array)
动态数组是一种非紧凑数组,其大小可以在运行时设定或更改。
- 未初始化的动态数组默认大小为0
- 动态数组的大小通过 new 构造函数或数组赋值来设定
- 动态数组支持所有变量数据类型作为元素类型,包括数组类型
- 动态数组的维度在数组声明中用
[]表示 - 多维数组声明中的任何非紧凑维度都可以是动态数组维度
1
2bit [3:0] nibble[]; // 4比特向量的动态数组
integer mem[2][]; // 固定大小非紧凑数组,包含2个动态整数数组
构造函数
new[]构造函数用于设置动态数组的大小并初始化其元素。当左侧表示动态数组时,它可出现在变量声明赋值的右侧表达式位置,以及阻塞过程赋值语句中。如果新的构造函数调用未指定初始化表达式,则数组元素将被初始化为其类型的默认值。可以用初始化表达式初始化动态数组。若提供该表达式,它必须是一个与左侧动态数组赋值兼容的数组。1
2
3int arr1 [][2][3] = new [4]; // arr1 初始化为长度为 4 的数组,其元素是固定大小的数组,故不需要初始化
int arr2 [][] = new [4]; // arr2 初始化为长度为 4 的数组,其元素也是动态数组,还未初始化
int arr3 [1][2][] = new [4]; // 错误,arr3 本身不是动态数组初始化数组的大小参数无需与初始化数组的实际尺寸完全匹配。当初始化数组的尺寸更大时,系统会将其截断以匹配指定的大小参数;当初始化数组尺寸较小时,系统会使用默认值填充数组以达到指定大小。(大小不一定匹配,但是元素类型必须赋值兼容)1
2int idest[], isrc[3] = '{5, 6, 7};
idest = new [3] (isrc); // 设置数组大小并初始化元素值为 {5, 6, 7}事实上,这种行为提供了一种在保留内容的同时调整动态数组大小的机制。可以通过将现有动态数组同时作为左侧项和初始化表达式来实现对其大小的调整。1
2
3
4int src[3], dest1[], dest2[];
src = '{2, 3, 4};
dest1 = new[2] (src); // dest1 的元素为 {2, 3}
dest2 = new[4] (src); // dest2 的元素为 {2, 3, 4, 0}使用1
2
3
4
5
6integer addr[]; // 声明动态数组
addr = new[100]; // 创建包含 100 个元素的数组
...
// 将数组大小加倍,同时保留原有值
// 注意:之前对 addr 元素的引用将失效
addr = new[200](addr);new对已初始化的动态数组进行大小调整或重新初始化是破坏性的操作:除非像前例那样用原有内容重新初始化,否则所有原有的数组数据都将丢失,且之前对数组元素的引用也会全部失效。
其他成员函数
size()方法返回动态数组的当前大小,如果数组尚未创建,则返回零。示例:1
function int size(); // 动态数组的 size 方法等同于 $size(addr, 1)1
2int j = addr.size;
addr = new[ addr.size() * 4 ] (addr); // 将 addr 数组的大小扩大为原来的四倍delete()方法会清空数组,使其成为零大小的数组。示例:1
function void delete();1
2
3int ab[] = new[N];
ab.delete;
$display("%d", ab.size); // 输出 0
数组赋值
- 任何向量表达式都可以赋值给任何紧凑数组
- 目标紧凑数组的紧凑数组边界不影响赋值
- 若无显式类型转换,紧凑数组不能直接赋值给非紧凑数组
- 关联数组仅与关联数组具有赋值兼容性
- 若满足以下所有条件,则固定大小的非紧凑数组、动态数组、队列或此类数组的切片应与其他同类数组或切片具有赋值兼容性:
- 源与目标的元素类型必须等价。
- 若目标为固定大小数组或切片,则源数组的元素数量必须与目标相同。
注意:此处的“元素”指变化最慢的数组维度的元素。这些元素本身可能属于某种非紧凑数组类型。
- 要使两个数组具有赋值兼容性,必须(但非充分)要求它们具有相同数量的非紧凑维度
- 非紧凑数组的赋值兼容性弱于类型等价性,因为它不要求变化最慢的维度具有相同的非紧凑数组种类(队列、动态或固定大小)。此弱化条件仅适用于变化最慢的维度。任何变化更快的维度必须满足等价性要求,整个数组才具有赋值兼容性
- 赋值应通过将源数组的每个元素赋给目标数组的对应元素来完成。元素间的对应关系由各数组中元素的从左到右顺序决定。例如,若数组 A 声明为 int A[7:0],数组 B 声明为 int B[1:8],则赋值 A=B; 会将元素 B[1] 赋给元素 A[7],依此类推
- 若赋值目标为队列或动态数组,其大小将调整为与源表达式具有相同数量的元素,随后按前述从左到右的元素对应关系进行赋值
- 若尝试将动态数组或队列复制到元素数量不同的固定大小目标数组中,将导致运行时错误且不会执行任何操作
作为函数参数
数组可以作为参数传递给子程序。按值传递数组参数的规则与数组赋值规则相同。当数组参数按值传递时,会向被调用的子程序传递该数组的副本。此规则适用于所有数组类型:固定大小数组、动态数组、队列或关联数组。
关联数组(Associative Array)
动态数组适用于处理数量动态变化的连续变量集合,而当集合大小未知或数据空间稀疏时,关联数组是更优选择。关联数组在使用前不会分配任何存储空间,其索引表达式不受限于整型表达式,可以是任意类型。关联数组实现了对其声明类型元素的查找表功能。用作索引的数据类型既作为查找键,也决定了元素的排列顺序。此数据结构相当于 C++ 中的 ordered_map。
- 声明关联数组的语法如下:其中:
1
data_type array_id [ index_type ];data_type表示数组元素的数据类型,可以是固定尺寸数组允许的任何类型array_id是被声明数组的名称index_type是用作索引的数据类型或*号。若指定为*,则数组可通过任意尺寸的整型表达式进行索引
关联数组的声明示例如下:1
2
3integer i_array[*]; // 整数关联数组(未指定索引类型)
bit [20:0] array_b[string]; // 21位向量的关联数组,通过字符串索引
event ev_array[myClass]; // 事件关联数组,通过myClass类进行索引
关联数组中的元素是动态分配的。当将不存在的关联数组元素用作赋值目标或通过引用传递的实际参数时,应为其分配一个条目。关联数组会根据索引数据类型维护已分配值的条目及其相对顺序。关联数组元素是非紧凑的。换言之,除复制或比较数组外,在大多数表达式中使用单个元素前,必须先从数组中将其选出。
索引方法
通配符索引
指定通配符索引类型的关联数组具有以下特性:
- 数组可通过任意整数表达式进行索引。由于索引表达式可能具有不同位宽,同一数值可能存在多种表示形式,且每种形式的位宽各不相同。SystemVerilog 通过去除前导零、计算最小位宽并使用该数值的对应表示形式来解决这一歧义。
- 非整数索引值是非法的,将导致错误
- 包含 x 或 z 的四值索引值无效
- 索引表达式为自确定类型,且被视为无符号数处理
- 字符串字面量索引会自动转换为等宽度的位向量。
- 排序方式为数值排序(从小到大)。
- 指定通配符索引类型的关联数组不得在 foreach 循环中使用,也不得与返回索引值或值数组的数组操作方法一起使用。
字符串索引
指定字符串索引的关联数组具有以下特性:
- 索引可以是任意长度的字符串或字符串字面量。其他类型均无效,将导致类型检查错误。
- 空字符串“”索引是有效的。
- 排序方式为字典序(从小到大)。
类索引
指定类索引的关联数组具有以下特性:
- 索引可以是该特定类型的对象或派生自该类型的对象。任何其他类型均无效,并会导致类型检查错误。
- 空索引是有效的。
- 排序是确定性的,但顺序任意。
整数索引
指定整数数据类型索引的关联数组应具备以下特性:
- 索引表达式应按转换为索引类型的方式求值,但禁止从实数或短实数数据类型进行隐式转换。
- 包含 x 或 z 的四值索引表达式无效。
- 排序方式为有符号或无符号数值排序,具体取决于索引类型的有符号性。
其他索引类型
通常,指定任意类型索引的关联数组具有以下特性:
- 声明的索引类型必须定义了相等运算符才合法。这包括所有动态大小的类型作为合法索引类型。但实数或短实数数据类型,或包含实数/短实数的类型,应视为非法索引类型。
- 索引表达式本身或其任何元素包含 x 或 z 时无效。
- 索引表达式本身或其任何元素包含空值或 null 时,不会导致索引无效。
- 若索引类型定义了关系运算符,排序规则遵循前述条款的定义。若未定义,此类关联数组中任意两个条目的相对顺序可能发生变化,甚至同一工具的不同次运行中也可能不同。但在同一仿真运行期间,只要未添加或删除索引,相对顺序应保持不变。
自动初始化
当不存在的关联数组元素被用作赋值目标或通过引用传递的实际参数时,应为其分配存储空间。某些结构在单个语句中同时执行读取和写入操作,例如递增操作。在这些情况下,应在引用该元素之前,使用其默认值或用户指定的初始值分配不存在的元素。例如:1
2
3
4
5
6
7int a[int] = '{default:1};
typedef struct { int x=1,y=2; } xy_t;
xy_t b[int];
begin
a[1]++;
b[2].x = 5;
end
假设在执行这些语句之前,a[1] 和 b[2] 的引用是不存在的元素。执行 a[1]++ 时,a[1] 将被分配并初始化为 1。递增后,a[1] 的值将变为2。执行 b[2].x = 5 时,b[2] 将被分配,b[2].x 的值为 1,b[2].y 的值为 2。执行赋值操作后,b[2].x 将被更新为 5。
内置成员函数
num()和size()方法返回关联数组中的条目数量。如果数组为空,它们将返回0。示例:1
2function int num();
function int size();1
2
3
4
5int imem[int];
imem[3] = 1;
imem[16'hffff] = 2;
imem[4'b1000] = 3;
$display("%0d entries\n", imem.num); // 输出"3 entries"delete()方法的语法如下:其中1
function void delete([input index]);index是适用于该数组类型的可选索引。- 如果指定了索引,则
delete()方法将删除指定索引处的条目。如果要删除的条目不存在,该方法不会发出警告。 - 如果未指定索引,则
delete()方法将删除数组中的所有元素。
示例:1
2
3
4
5
6int map[string];
map["hello"] = 1;
map["sad"] = 2;
map["world"] = 3;
map.delete("sad"); // 从 map 中删除索引为"sad"的条目
map.delete; // 从关联数组 map 中删除所有条目
exists()函数检查给定数组中指定索引处是否存在元素。如果元素存在则返回1;否则返回0。其中index是适用于该数组类型的索引。1
function int exists(input index);
示例:1
2
3
4if (map.exists("hello"))
map["hello"] += 1;
else
map["hello"] = 0;first()和last()方法分别将关联数组中第一个(最小)和最后一个(最大)索引的值赋给给定的索引变量。如果数组为空,则返回 0;否则返回 1。其中index是适用于该数组类型的索引。不允许使用指定通配符索引类型的关联数组。1
2function int first(ref index);
function int last(ref index);
示例:1
2
3
4
5string s;
if ( map.first( s ) )
$display( "第一个条目为:map[ %s ] = %0d\n", s, map[s] );
if ( map.last( s ) )
$display( "最后一个条目为:map[ %s ] = %0d\n", s, map[s] );next()和prev()方法分别查找大于/小于给定索引参数的最小索引。若存在下一个/上一个条目,则将索引变量赋值为该条目的索引,函数返回 1;否则索引保持不变,函数返回 0。其中 index 是适用于当前数组的对应类型索引。不允许使用指定通配符索引类型的关联数组。1
function int next( ref index );
示例:1
2
3
4
5
6
7
8
9string s;
if ( map.first( s ) ) begin
do
$display( "%s : %d\n", s, map[ s ] );
while ( map.next( s ) );
do
$display( "%s : %d\n", s, map[ s ] );
while ( map.prev( s ) );
end
传递给四个关联数组遍历方法 first()、last()、next() 和 prev() 的参数必须与数组的索引类型赋值兼容。如果参数为整型且其位宽小于对应数组索引类型的位宽,则函数返回 -1,并会对索引值进行截断以适配参数。例如:1
2
3
4
5
6string aa[int];
byte ix;
int status;
aa[ 1000 ] = "a";
status = aa.first( ix ); // status 为 -1
// ix 为 232(1000 的最低 8 位)
赋值与传参
- 关联数组只能赋值给具有兼容类型且索引类型相同的另一个关联数组
- 其他类型的数组(无论是固定大小数组还是动态数组)不能赋值给关联数组,关联数组也不能赋值给其他类型的数组
- 将一个关联数组赋值给另一个关联数组时,目标数组中原有的所有条目将被清空,随后源数组中的每个条目会复制到目标数组中。
- 关联数组只能作为参数传递给具有兼容类型且索引类型相同的关联数组
- 其他类型的数组(无论是固定大小数组还是动态数组)不能传递给以关联数组为形参的子程序。
- 关联数组也不能传递给接受其他类型数组的子程序
- 按值传递关联数组会创建该关联数组的本地副本
字面量与默认值
关联数组字面量使用 '{index:value} 语法,并可包含可选的默认索引。与所有其他数组类似,关联数组可以逐条写入条目,也可以通过数组字面量一次性替换整个数组内容。1
2
3
4// 以二值整数为索引的字符串关联数组,默认值为 "hello"
string words [int] = '{default: "hello"};
// 以字符串为索引的四值整数关联数组,默认值为 -1
integer tab [string] = '{"Peter":20, "Paul":22, "Mary":23, default:-1 };
若指定了默认值,则读取不存在的元素将返回该默认值且不会发出警告。否则,将返回表(无效索引)中规定的值。定义默认值不会影响关联数组方法的操作。
队列(Queue)
队列是一种可变大小、有序的同类型元素集合。
- 队列支持对其所有元素进行常数时间访问,以及在队列首尾进行常数时间的插入与删除操作
- 队列中的每个元素通过一个序数来标识其位置,其中
0代表第一个元素,$代表最后一个元素 - 队列类似于一个可自动增长和收缩的一维非紧凑数组
- 与数组类似,队列可以使用索引、连接、切片操作符语法以及相等运算符进行操作
- 队列的声明语法与非紧凑数组相同,但需将数组大小指定为
$ - 队列的最大容量可通过指定其可选的右边界(最后一个索引)来限制
- 队列值可以通过赋值模式或非紧凑数组连接来写入
例如:1
2
3
4byte q1[$]; // 一个字节队列
string names[$] = { "Bob" }; // 包含一个元素的字符串队列
integer Q[$] = { 3, 2, 7 }; // 已初始化的整数队列
bit q2[$:255]; // 最大容量为256位的位队列
如果在声明时未提供初始值,队列变量将被初始化为空队列。空队列可以用空的非紧凑数组拼接符号 {} 表示。
基础操作
队列应支持可对非紧凑数组执行的所有操作。此外,队列还应支持以下操作:
- 队列应能自动调整大小以容纳写入其中的任何队列值,但其最大容量可能受限于用户定义。
- 在队列切片表达式(例如
Q[a:b])中,切片边界可以是任意整数表达式,且无需为常量表达式。
与数组不同,空队列 {} 是一个有效的队列,也是某些队列操作的结果。以下规则适用于队列操作符:
Q[a:b]生成一个包含b - a + 1个元素的队列。- 若
a > b,则Q[a:b]生成空队列{}。 Q[n:n]生成一个仅包含位置n处元素的队列,即Q[n:n] === { Q[n] }。- 若
n超出Q的范围(n < 0或n > $),则Q[n:n]生成空队列{}。 - 若
a或b是包含 x 或 z 值的四值表达式,则生成空队列{}。
- 若
- 当
a < 0时,Q[a:b]等同于Q[0:b]。 - 当
b > $时,Q[a:b]等同于Q[a:$]。 - 无效的索引值(即包含一个或多个 x 或 z 位的四值表达式,或超出
0...$范围的值)将导致读取操作返回适用于队列元素类型中不存在数组条目的值(无效索引)。 - 无效的索引(即包含 x 或 z 的四值表达式,或超出
0...$+1范围的值)将导致写入操作被忽略,并发出运行时警告;但写入Q[$+1]是合法的。 - 使用语法
[$:N]声明右边界限的队列称为有界队列,其索引不得超过N(其大小不得超过N+1)。
内置成员函数
假设有如下定义:1
2
3
4
5typedef mytype element_t; // mytype 是一个合法的 queue 值类型
typedef element_t queue_t[$];
element_t e;
queue_t Q;
int i;
size()方法返回队列中的元素数量。若队列为空,则返回 0。示例:1
function int size();1
2for ( int j = 0; j < Q.size; j++ )
$display( Q[j] );insert()方法将指定元素插入到给定的索引位置。若索引参数包含未知值(x/z)的位,或为负数,或大于队列当前长度,则该方法调用不会对队列产生任何影响,并可能触发警告信息。(索引参数的类型为 integer 而非 int,以便能够检测调用方实际参数值中的 x/z 值)1
function void insert(input integer index, input element_t item);delete()方法的原型如下:其中 index 为可选索引。1
function void delete( [input integer index] );- 若未指定索引,则
delete()方法将删除队列中的所有元素,使队列变为空。 若指定了索引,则
delete()方法将删除指定索引位置的元素。若索引参数中存在未知(x/z)值位,或为负数,或大于等于队列当前大小,则该方法调用对队列无影响,并可能触发警告。pop_front()和pop_back()方法分别移除并返回队列的第一个元素/最后一个元素。1
2function element_t pop_front();
function element_t pop_back();若在空队列上调用此方法:
- 其返回值应与尝试读取与队列元素类型相同的非数组成员时获得的值相同(无效索引);
对队列无影响,并可能触发警告。
push_front()和push_back()方法将给定元素插入队列的前端/末尾。1
2function void push_front(input element_t item);
function void push_back(input element_t item);
元素引用的持久性
队列元素可能通过引用传递给某个任务,该任务在对队列执行其他操作时持续持有该引用。对队列的某些操作会导致此类引用失效:
- 当使用任何队列方法更新队列时,未被该方法删除的现有元素的引用不失效。所有被该方法从队列中移除的元素将变为失效引用。
- 当赋值目标为整个队列时,对原队列中所有元素的引用均失效。
- 使用非紧凑数组连接语法在队列中插入元素将导致对现有队列所有元素的引用失效
- 使用
delete、pop_front和pop_back方法将使被弹出或删除元素的引用失效,但队列中其他所有元素的引用不受影响。 - 对队列使用
insert、push_back和push_front方法通常不会导致引用失效(例外情况是:对有界队列执行insert或push_front操作时,若新队列大小超过其边界,将导致队列中编号最大的元素被删除)。
队列更新方法
1 | |
以下示例展示了一些无法通过单一队列方法调用实现的有用操作。与前述示例相同,对队列变量的赋值操作会使对其元素的任何引用失效。1
2q = q[2:$]; // 丢掉前两项的新队列
q = q[1:$-1]; // 丢掉首项和末项的新队列
有界队列
有界队列不得包含索引高于队列声明上界的元素。对有界队列的操作应表现得与无界队列完全相同,区别在于:在对有界队列变量执行任何写入操作后,若该变量存在超出其界限的元素,则所有此类越界元素都应被丢弃,并发出警告。(一般来说是索引值最大的项目被丢弃)
数组查询系统函数
SystemVerilog 提供了系统函数,用于返回关于数组或整数数据类型特定维度,或此类数据类型数据对象的信息。
- 返回类型为整数
- 可选维度表达式的默认值为1
- 维度表达式可以指定任何固定大小的维度(紧凑或非紧凑)或任何动态大小的维度(动态数组、关联数组或队列)
- 当用于动态数组或队列维度时,这些函数返回数组当前状态的信息
对于除关联数组维度外的任何维度:
$left应返回维度的左边界。对于紧凑维度,这是最高有效元素(MSB)的索引;对于队列或动态数组维度,$left应返回 0。$right应返回维度的右边界。对于紧凑维度,这是最低有效元素(LSB)的索引;对于当前大小为 0 的队列或动态数组维度,$right应返回 -1。- 对于固定大小的维度,如果
$left大于或等于$right,$increment应返回 1;如果$left小于$right,则返回 -1。对于队列或动态数组维度,$increment应返回 -1。 $low应返回与$left相同的值(如果$increment返回 -1),或与$right相同的值(如果$increment返回 1),即$left和$right里较小的那一个。$high应返回与$right相同的值(如果$increment返回 -1),或与$left相同的值(如果$increment返回 1),即$left和$right里较大的那一个。$size应返回维度中的元素数量,其等价于:$high – $low + 1。$dimensions应返回以下内容:- 对于紧凑和非紧凑,静态或动态数组,返回总维度数
- 对于字符串数据类型或任何其他等同于位向量类型的非数组类型,返回 1
- 对于任何其他类型,返回 0
$unpacked_dimensions应返回以下内容:- 对于静态或动态数组,返回非紧凑维度总数
- 对于任何其他类型,返回 0
数组的维度编号规则如下:变化最慢的维度(紧凑或非紧凑)为维度 1。变化较快的维度依次具有更高的维度编号。在编号维度之前,中间类型定义会首先展开。
例如:1
2
3
4
5// 维度编号
// 3 4 1 2
logic [3:0][2:1] n [1:5][2:8];
typedef logic [3:0][2:1] packed_reg;
packed_reg n[1:5][2:8]; // 与上面定义的维度相同- 对于固定大小的整数类型(
integer、shortint、longint和byte),维度 1 是预定义的。对于未声明范围说明符的整数N,其边界假定为[$bits(N)-1:0]。 - 如果数组查询函数的第一个参数会导致
$dimensions返回 0,或者第二个参数超出范围,则应返回'x。 - 直接在动态大小的类型标识符上使用这些函数是错误的
- 对于关联数组维度的使用仅限于具有整数值的索引类型。对于整数索引,这些函数返回以下值:
$left返回 0。$right返回可能的最高索引值。$low返回当前分配的最低索引值,但如果当前未分配任何元素,则返回'x。$high返回当前分配的最大索引值,但如果当前未分配任何元素,则返回'x。$increment返回 -1。$size返回当前分配的元素数量。
如果以下三个条件均成立,则在常量表达式中调用这些查询函数是合法的:
- 该调用在表达式中是合法的
- 应用于第一个参数的类型运算符是合法的,并返回某个固定大小的类型
- 任何可选的维度表达式均为常量表达式
对多个变量维度的查询
如果使用参数 (v, n) 调用数组查询系统函数,其中 v 表示某个数组变量,且 n 大于 1,那么当 n 所指示的维度是可变大小的维度时,将会产生错误。以下示例说明了这一限制。该限制不影响 $dimensions 或 $unpacked_dimensions 函数,因为它们不接受第二个参数。1
2
3
4
5
6
7
8
9int a[3][][5]; // 数组维度 2 具有可变大小
$display( $unpacked_dimensions(a) ); // 显示 3
a[2] = new[4];
a[2][2][0] = 220; // 正确,a[2][2] 是一个包含 5 个元素的数组
$display( $size(a, 1) ); // 正确,显示 3
$display( $size(a, 2) ); // 错误,维度 2 是动态的
$display( $size(a[2], 1) ); // 正确,显示 4(a[2] 是一个包含 4 个元素的动态数组)
$display( $size(a[1], 1) ); // 正确,显示 0(a[1] 是一个空的动态数组)
$display( $size(a, 3) ); // 正确,显示 5(固定大小的维度)
通用数组操作函数
SystemVerilog 提供了多种内置方法,以便于进行数组的搜索、排序和归约操作。1
2array_method_call ::=
expression . array_method_name { attribute_instance } [ ( iterator_argument ) ] [ with ( expression ) ]
可以在函数调用后加一个 with 子句,然后跟一个用括号括起来的表达式。
- 如果 with 子句中包含的表达式一般不能有任何副作用,否则结果可能无法预测
- 数组操作方法会遍历数组元素,然后使用这些元素来评估 with 子句指定的表达式
- iterator_argument 可选地指定了 with 表达式在每次迭代中用于表示数组元素的变量名称。如果未指定,默认使用名称 item
- iterator_argument 的作用域仅限于 with 表达式。仅指定 iterator_argument 而不指定 with 子句是非法的
数组定位方法
数组定位方法可作用于任何非紧凑的数组(包括队列),但其返回类型为队列。这些定位方法允许在数组中搜索满足特定表达式的元素(或其索引)。
- 数组定位方法会以未指定的顺序遍历数组。
- 索引定位器方法为所有数组返回一个整数队列,但关联数组除外,后者返回一个与关联索引类型相同的队列。
- 不允许指定通配符索引类型的关联数组。
- 如果没有任何元素满足给定表达式,或者数组为空(对于队列或动态数组),则返回一个空队列。
- 索引定位器方法返回一个包含所有满足表达式的元素索引的队列。
- 由
with子句指定的可选表达式必须求值为布尔值。
支持以下定位器方法(with 子句是必需的):
find():返回所有满足给定表达式的元素。find_index():返回所有满足给定表达式的元素的索引。find_first():返回第一个满足给定表达式的元素。find_first_index():返回第一个满足给定表达式的元素的索引。find_last():返回最后一个满足给定表达式的元素。find_last_index():返回最后一个满足给定表达式的元素的索引。
第一个或最后一个元素分别定义为最靠近最左端或最右端(注意不是索引最大最小)索引的元素,但关联数组除外,关联数组使用最接近关联数组索引类型的 first 或 last 方法返回的索引的元素。
对于以下定位方法,如果给定数组的元素类型已定义关系运算符(<、>、==),则可省略 with 子句(及其表达式)。若指定了 with 子句,则必须为该表达式的类型定义关系运算符(<、>、==)。
min()返回具有最小值或其表达式计算结果为最小值的元素。max()返回具有最大值或其表达式计算结果为最大值的元素。unique()返回所有具有唯一值或其表达式计算结果为唯一值的元素。返回的队列为数组中出现的每个值包含且仅包含一个条目,返回元素的顺序与原始数组的顺序无关。unique_index()返回所有具有唯一值或其表达式计算结果为唯一值的元素的索引。返回的队列为数组中出现的每个值包含且仅包含一个条目,返回元素的顺序与原始数组的顺序无关。对于重复值的条目,返回的索引可能是其中任意一个重复值的索引。
1 | |
数组排序方法
数组排序方法用于重新排列除关联数组外的任何非紧凑数组(固定大小或动态大小)的元素。排序方法的原型如下:1
function void ordering_method ( array_type iterator = item );
支持的排序方法包括:
reverse()反转数组中元素的顺序。不能有 with 子句,否则将导致编译错误。sort()按升序对数组进行排序,可选择使用 with 子句中的表达式。若数组元素类型已定义关系运算符(<、>、==),则 with 子句(及其表达式)是可选的。若指定了 with 子句,则必须为表达式类型定义关系运算符(<、>、==)。rsort()按降序对数组进行排序,可选择使用 with 子句中的表达式。若数组元素类型已定义关系运算符(<、>、==),则 with 子句(及其表达式)是可选的。若指定了 with 子句,则必须为表达式类型定义关系运算符(<、>、==)。shuffle()随机打乱数组中元素的顺序。不能有 with 子句,否则将导致编译错误。
1 | |
数组归约方法
数组归约方法可应用于任何整数值的非紧凑数组,以将数组归约为单一值。可选的 with 子句中的表达式用于指定归约过程中使用的数值。该方法通过为每个数组元素计算此表达式产生的值进行归约操作。这与数组定位方法形成对比——在数组定位方法中,with 子句是作为选择条件使用的。
这些方法的原型如下:1
function expression_or_array_type reduction_method (array_type iterator = item);
该方法返回一个与数组元素类型相同的单一值,或者如果指定了 with 子句,则返回该表达式的类型。如果数组元素类型已定义了相应的算术或布尔归约操作,则可以省略 with 子句。如果指定了 with 子句,则必须为该表达式的类型定义相应的算术或布尔归约操作。
支持的归约方法包括:
sum()返回所有数组元素的总和,如果指定了 with 子句,则返回对每个数组元素求值表达式所得值的总和。product()返回所有数组元素的乘积,如果指定了 with 子句,则返回对每个数组元素求值表达式所得值的乘积。and()返回所有数组元素的按位与(&),如果指定了 with 子句,则返回对每个数组元素求值表达式所得值的按位与。or()返回所有数组元素的按位或(|),如果指定了 with 子句,则返回对每个数组元素求值表达式所得值的按位或。xor()返回所有数组元素的按位异或(^),如果指定了 with 子句,则返回对每个数组元素求值表达式所得值的按位异或。
1 | |
最后一个示例展示了如何强制对位数组调用 sum 的结果为 32 位。默认情况下,在此示例中调用 sum 的结果类型为 logic。对 1024 位的值求和可能导致结果溢出。通过使用 with 子句可以避免这种溢出。当指定 with 子句时,它用于确定结果的类型。在 with 子句中将 item 强制转换为 int 会导致数组元素在求和前被扩展为 32 位。在此示例中调用 sum 的结果为 32 位,因为归约方法结果的宽度应与 with 子句中表达式的宽度相同。
迭代器索引查询
数组操作方法所使用的表达式有时需要每次迭代时的实际数组索引,而不仅仅是数组元素。迭代器的索引方法返回指定维度的索引值。该索引方法的原型如下:1
function int_or_index_type index ( int dimension = 1 );
对于除关联数组外的所有数组迭代项,索引方法的返回类型为int;关联数组则返回与其关联索引类型相同的索引。不允许指定通配符索引类型的关联数组。1
2
3
4
5int arr[];
int q[$];
...
// 查找所有值等于其位置(索引)的项
q = arr.find with ( item == item.index );
第六章 类(Class)类型
类是一种包含数据及操作这些数据的子程序(函数和任务)的类型。类的数据被称为类属性,其子程序则称为方法;二者共同构成类的成员。类属性与方法共同定义了某类对象的内容与功能。
例如,数据包可以是一个对象,它可能包含命令字段、地址、序列号、时间戳以及数据包载荷。此外,对数据包可执行多种操作:初始化数据包、设置命令、读取数据包状态或校验序列号。每个数据包各不相同,但作为一类对象,数据包具有某些可通过定义来描述的固有属性。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33class Packet ;
// 数据(或者叫类属性)
bit [3:0] command;
bit [40:0] address;
bit [4:0] master_id;
integer time_requested;
integer time_issued;
integer status;
typedef enum { ERR_OVERFLOW = 10, ERR_UNDERFLOW = 1123} PCKT_TYPE;
const integer buffer_size = 100;
const integer header_size;
// 类构造函数
function new();
command = 4'd0;
address = 41'b0;
master_id = 5'bx;
header_size = 10;
endfunction
// 类方法
task clean();
command = 0; address = 0; master_id = 5'bx;
endtask
task issue_request( int delay );
// send request to bus
endtask
function integer current_status();
current_status = status;
endfunction
endclass
面向对象的类扩展允许动态创建和销毁对象。类实例(即对象)可以通过对象句柄进行传递,这提供了安全指针功能。对象可被声明为具有输入、输出、双向或引用方向的参数。无论何种情况,参数传递时复制的都是对象句柄,而非对象本身的内容。
SystemVerilog 不需要像 C++ 那样进行复杂的内存分配与释放。对象的构建过程简单直接;并且像 Java 一样,垃圾回收是隐式且自动进行的,因此不会出现内存泄漏或其他难以察觉的问题。
从表面上看,类(class)和结构体(struct)似乎提供了相似的功能,可能让人觉得只需其中一种即可。然而事实并非如此;类在以下三个基本方面与结构体存在差异:
- SystemVerilog 结构体是严格的静态对象;它们要么在静态内存区域(全局或模块作用域)中创建,要么在自动任务的栈上分配。相反,SystemVerilog 对象(即类实例)完全是动态的;声明类并不会创建对象,必须通过调用
new方法来创建对象。 - SystemVerilog 对象通过句柄实现,从而提供了类似 C 语言指针的功能。但 SystemVerilog 禁止将句柄强制转换为其他数据类型,因此 SystemVerilog 句柄不存在 C 指针相关的风险。
- SystemVerilog 对象构成了面向对象数据抽象的基础,这种抽象提供了真正的多态性。类继承、抽象类和动态类型转换是强大的机制,它们远远超越了结构体所提供的简单封装机制。
对象(类实例)
类定义了一种数据类型。对象是该类的一个实例。使用对象时,首先声明一个该类的变量(该变量持有对象句柄),然后创建该类的一个对象(使用 new 函数)并将其赋值给该变量。1
2Packet p; // 声明一个 Packet 类的变量
p = new; // 将变量初始化为 Packet 类新分配的对象
变量 p 被称为持有 Packet 类对象的对象句柄。
默认情况下,未初始化的对象句柄会被设置为特殊值 null。可以通过将其句柄与 null 进行比较来检测未初始化的对象。
通过 null 对象句柄访问非静态成员或虚方法是非法的。通过 null 对象进行非法访问的结果是不确定的,实现时可能会报错。
SystemVerilog 对象使用对象句柄进行引用。C 指针与 SystemVerilog 对象句柄之间存在一些差异。C 指针为程序员提供了更大的使用自由度,而 SystemVerilog 对象句柄的使用规则则更为严格。例如,C 指针可以递增,但 SystemVerilog 对象句柄不能。除了对象句柄外,、还引入了 chandle 数据类型,用于 DPI。
| 操作 | C 指针 | SV 对象句柄 | SV chandle |
|---|---|---|---|
| 算术运算 | 允许 | 不允许 | 不允许 |
| 引用任意数据类型 | 允许 | 不允许 | 不允许 |
null 值解引用 |
错误 | 错误 | 不允许 |
| 类型转换 | 允许 | 受限允许 | 不允许 |
| 分配给数据类型的地址 | 允许 | 不允许 | 不允许 |
| 未引用的对象会被垃圾回收 | 否 | 是 | 否 |
| 默认值 | 未定义的 | null |
null |
| 引用类类型 | 需要C++ | 允许 | 不允许 |
仅以下运算符对对象句柄有效:
- 与另一个类对象或
null的相等(==)与不等(!=)比较。被比较的对象之一必须与另一个对象在赋值上兼容。 - 与另一个类对象或
null的严格相等(===)与严格不等(!==)(语义与==和!=相同)。 - 条件运算符
- 对类数据类型与目标类对象在赋值上兼容的类对象进行赋值
- 对
null的赋值
对象属性与对象参数数据
类属性的数据类型不受限制。对象的类属性可通过使用实例名限定类属性名来访问。沿用之前的示例,数据包对象p的属性可按如下方式使用:1
2
3
4
5
6Packet p = new;
int var1;
p.command = INIT;
p.address = $random;
packet_time = p.time_requested;
var1 = p.buffer_size;
除了可通过类作用域解析运算符访问外,类的枚举名还可通过使用实例名限定类枚举名来访问:1
initial $display(p.ERR_OVERFLOW);
对象的参数数据值同样可通过使用实例名限定类值参数或局部值参数名来访问。此类表达式不属于常量表达式。不允许通过类句柄访问数据类型,例如:1
2
3
4
5
6
7class vector #(parameter width = 7, type T = int);
endclass
vector #(3) v = new;
initial $display (vector #(3)::T'(3.45)); // 类型转换
initial $display ((v.T)'(3.45)); // 非法操作
initial $display (v.width);
对象方法
对象的成员方法可以通过与访问类属性相同的语法来调用:1
2Packet p = new;
status = p.current_status();
上述对 status 的赋值不能写成:status = current_status(p);
对象具有自包含性,通过自身的方法操作自身的属性。因此,对象无需作为参数传递给 current_status()。类的属性可被该类的所有方法自由广泛地访问,但每个方法仅访问与其所属对象(即实例)关联的属性。声明为类类型组成部分的方法具有自动生命周期,声明具有静态生命周期的类方法是非法的。
构造函数
当创建一个对象时:1
Packet p = new;
系统会执行与该类关联的 new 函数:1
2
3
4
5
6class Packet;
integer command;
function new();
command = IDLE;
endfunction
endclass
如前所示,new 现在被用于两个语义完全不同的上下文。变量声明会创建一个 Packet 类的对象。在创建该实例的过程中,系统会调用 new 函数,以便执行任何所需的特殊初始化操作。new 函数也被称为类的构造函数。
new操作被定义为一个没有返回类型的函数,并且与其他函数一样,它应当是非阻塞的- 尽管
new没有指定返回类型,但赋值语句的左侧决定了返回类型 - 如果一个类没有提供显式的用户自定义
new方法,系统将自动提供一个隐式的new方法 - 派生类的
new方法应首先调用其基类的构造函数super.new() - 在基类构造函数调用(如果有)完成后,类中定义的每个属性都应初始化为其显式默认值,如果没有提供默认值,则初始化为未初始化值
- 属性初始化后,用户自定义构造函数中的其余代码将被执行。默认构造函数在属性初始化后没有额外效果。属性在初始化之前的值是未定义的。
- 参数的约定与其他任何过程性子程序调用相同,例如默认参数的使用
- 构造函数可以被声明为局部或受保护的方法
- 构造函数不应被声明为静态方法或虚方法
限定类型的构造函数调用
一般情况下调用构造函数时要求所构造对象的类型必须与赋值目标类型相匹配,但另一种形式的构造函数调用通过在 new 关键字前直接添加类作用域(class_scope),独立于赋值目标指定被构造对象的类型。所指定的类型必须与目标类型保持赋值兼容性。1
2
3class C; ... endclass
class D extends C; ... endclass
C c = D::new; // 父类类型 C 的变量 c 现在引用了新构造的 D 类型对象
注意:这种类型化构造函数调用的效果相当于声明并构造一个 D 类型的临时变量,然后将其复制到变量 c 中,如下例片段所示:1
2D d = new;
C c = d;
静态类属性
有时只需要一个能被所有实例共享的变量。这类类属性需使用关键字 static 创建。例如,在以下场景中,类的所有实例需要访问同一个文件描述符:1
2class Packet ;
static integer fileID = $fopen( "data", "r" );
此时,fileID 仅会被创建和初始化一次。此后,每个 Packet 对象都可以通过常规方式访问该文件描述符:1
2Packet p;
c = $fgetc( p.fileID );
静态类属性无需创建该类型的对象即可使用。
静态方法
方法可声明为静态。静态方法遵循所有类作用域和访问规则,但其行为类似于可在类外部调用的常规子程序,甚至无需实例化类。
- 静态方法无法访问非静态成员(类属性或方法),但可以直接访问静态类属性或调用同一类的静态方法
- 在静态方法体内访问非静态成员或特殊句柄
this属于非法操作,会导致编译错误 - 静态方法不能声明为虚方法静态方法与具有静态生命周期的任务不同。前者指方法在类中的生命周期,而后者指任务内参数和变量的生命周期。
1
2
3
4
5
6class id;
static int current = 0;
static function int next_id();
next_id = ++current; // 允许访问静态类属性
endfunction
endclass1
2
3
4class TwoTasks;
static task t1(); ... endtask // 静态类方法,其中的变量时自动变量(占用栈空间)
task static t2(); ... endtask // 非法定义:非静态的类方法不能有静态变量
endclass
this 关键字
this 关键字用于明确引用当前实例的类属性、值参数、局部值参数或方法。this 关键字表示一个预定义的对象句柄,它指向调用当前所在子例程的对象。this 关键字仅可在非静态类方法、约束、内联约束方法或嵌入类内的覆盖组中使用;否则将报错。例如,以下声明是编写初始化任务的常见方式:1
2
3
4
5
6class Demo ;
integer x;
function new (integer x);
this.x = x;
endfunction
endclass
在此示例中,x 既是类的一个属性,也是函数 new 的一个参数。在函数 new 中,对 x 的非限定引用应通过查找最内层作用域来解决,在本例中,即子程序参数声明。要访问实例类属性,需使用 this 关键字进行限定,以指向当前实例。
赋值、重命名与复制
声明类变量仅创建用于标识对象的名称。因此,Packet p1; 创建了一个变量 p1,该变量可保存 Packet 类对象的句柄,但 p1 的初始值为 null。在创建 Packet 类型的实例之前,对象并不存在,且 p1 不包含实际句柄:1
p1 = new;
因此,若声明另一个变量并将旧句柄 p1 赋值给新变量,例如:1
2Packet p2;
p2 = p1;
此时仍然仅存在一个对象,该对象可通过名称 p1 或 p2 进行引用。在此示例中,new 仅执行一次,故仅创建了一个对象。
然而,若将上述示例改写如下,则会生成 p1 的副本:1
2
3
4Packet p1;
Packet p2;
p1 = new;
p2 = new p1;
最后一条语句第二次执行 new,从而创建新对象 p2,其类属性从 p1 复制而来。这称为浅拷贝。所有变量(整型、字符串、实例句柄等)均被复制,但对象本身不会被复制,仅复制其句柄;如前所述,这相当于为同一对象创建了两个名称。即使类声明中包含实例化运算符 new,此规则依然成立。
- 使用类型化构造函数调用进行浅拷贝是非法的
- 浅拷贝按以下方式执行:
- 分配一个待复制的类类型对象。该分配过程不调用对象的构造函数,也不执行任何变量声明的初始化赋值
- 所有类属性,包括用于随机化和覆盖的内部状态,都将被复制到新对象中。对象句柄会被复制,这包括覆盖组对象的句柄。但嵌入式覆盖组例外,新对象中嵌入式覆盖组的对象句柄应设为空。
- 随机化内部状态,包括随机数生成器(RNG)状态、约束的约束模式状态、随机变量的随机模式状态,以及循环随机变量的循环状态。
- 新创建对象的句柄将被赋值给左侧的变量。
- 要实现完整(深度)拷贝,即复制所有内容(包括嵌套对象),通常需要编写自定义代码
继承与子类
SystemVerilog 提供的继承机制是单继承,即每个类都派生自一个基类。前面的子句定义了一个名为 Packet 的类。该类可以被扩展,以便将数据包链接成一个列表。创建一个名为 LinkedPacket 的新类,由于 LinkedPacket 是 Packet 的一种特殊形式,更优雅的解决方案是通过扩展类创建一个新的子类,该子类继承基类的成员。例如:1
2
3
4
5
6
7class LinkedPacket extends Packet;
LinkedPacket next;
function LinkedPacket get_next();
get_next = next;
endfunction
endclass
现在,Packet 的所有方法和类属性都成为 LinkedPacket 的一部分(就像它们在 LinkedPacket 中定义一样),并且 LinkedPacket 还具有额外的类属性和方法。
基类的方法也可以被重写以更改其定义。
重写成员
子类对象同样可以作为其基类的合法代表对象。子类对象的句柄可以被赋值给父类变量。1
2LinkedPacket lp = new;
Packet p = lp;
在这种情况下,通过 p 引用的将是 Packet 类的方法和类属性。举例来说,如果 LinkedPacket 中的类属性和方法被重写,那么通过 p 引用的这些被重写的成员将指向 Packet 类中的原始成员。从 p 的角度来看,LinkedPacket 中所有被重写的成员以及新增成员现在都被隐藏了。
要通过基类对象(示例中的 p)调用被重写的方法,该方法需要声明为 virtual。
super 关键字
super 关键字用于在派生类中引用基类的成员、类值参数或局部值参数。当派生类覆盖了基类的成员、值参数或局部值参数时,必须使用 super 来访问这些基类元素。使用 super 访问值参数或局部值参数的表达式不属于常量表达式。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15class Packet;
integer value; // 基类成员
function integer delay();
delay = value * value;
endfunction
endclass
class LinkedPacket extends Packet;
integer value; // 派生类成员
function integer delay();
delay = super.delay() + value * super.value; // 通过super访问基类成员
endfunction
endclass
- 成员、值参数或局部值参数可在上一层级声明,或由上一层级的类继承。无法跨越多层级访问(例如,不允许使用super.super.count)。
- 子类(或派生类)是当前类的扩展类,而超类(基类)是当前类所继承的类,从原始基类开始逐级延伸。
super.new调用必须是构造函数中首先执行的语句。这是因为必须在当前类初始化之前先初始化超类,如果用户代码未提供初始化操作,编译器将自动插入对super.new的调用。- 如果在扩展类时指定了参数,则子类构造函数不应包含
super.new()调用。
类的类型转换
将子类类型的表达式赋值给继承树中更高层级的类类型变量(即表达式类型的超类或祖先类)始终是合法的。而直接将超类类型的变量赋值给其子类类型的变量是非法的。不过,若超类句柄所引用的对象与子类变量具有赋值兼容性,则可以使用 $cast 将超类句柄赋值给子类类型的变量。
为检查赋值是否合法,需使用动态转换函数 $cast:$cast 的函数原型如下:function int $cast( singular dest_var, singular source_exp );
或task $cast( singular dest_var, singular source_exp );
当 $cast 应用于类句柄时,仅在以下三种情况下会成功:
- 源表达式与目标类型具有赋值兼容性,即目标类型与源表达式类型相同或是其超类
- 源表达式的类型与目标类型具有强制转换兼容性,即满足以下任一条件:
- 源表达式的类型是目标类型的超类,且源对象与目标类型具有赋值兼容性。
- 源表达式的类型是接口类,且源对象与目标类型具有赋值兼容性。
- 源表达式为字面常量
null
在所有其他情况下,$cast 均会失败,尤其是当源类型与目标类型不具备强制转换兼容性时——即使源表达式的求值结果为 null 也不例外。
若 $cast 成功,则执行赋值操作;否则,返回0。
数据隐藏与封装
在 SystemVerilog 中,未限定的类属性和方法默认是公共的,任何能够访问对象名称的人都可以使用它们。通常,需要通过隐藏类属性和方法的名称来限制从类外部对它们的访问。这可以防止其他程序员依赖特定的实现方式,同时避免对类内部属性进行意外修改。当所有数据都被隐藏(即仅通过公共方法访问)时,代码的测试和维护会变得容易得多。
类参数和类局部参数也是公共的。
- 类成员可以被标识为 local 或 protected
- 类属性可以进一步定义为 const,方法可以定义为 virtual
- 这些修饰符的指定顺序没有预定义规则
- 每个修饰符在每个成员中只能出现一次
- 将成员同时定义为 local 和 protected,或重复使用任何其他修饰符都是错误的。
- 被标识为 local 的成员仅对类内部的方法可见。此外,这些局部成员在子类中不可见。当然,访问局部类属性或方法的非局部方法可以被继承,并作为子类的方法正常工作。
- protected 类属性或方法具有局部成员的所有特性,但它可以被继承;它对子类可见。
- 将类构造函数声明为 local 方法会使该类不可扩展,因为子类中对
super.new()的引用将是非法的 - 在同一类内部,可以引用该类的局部方法或类属性,即使它位于同一类的不同实例中。从严格的封装角度来说,可能会认为
1
2
3
4
5
6class Packet;
local integer i;
function integer compare (Packet other);
compare = (this.i == other.i);
endfunction
endclassother.i不应在此数据包内部可见,因为它是从其实例外部引用的局部类属性。然而,在同一类内部,这种引用是允许的。在这种情况下,this.i将与other.i进行比较,并返回逻辑比较的结果。
常量类属性
类属性可以通过 const 声明变为只读,这与 SystemVerilog 中的其他变量类似。然而,由于类对象是动态对象,类属性支持两种形式的只读变量:全局常量和实例常量。
全局常量类属性在声明时包含初始值。它们与其他 const 变量的相似之处在于,除了声明时赋值外,不能在其它任何地方被赋值。1
2
3
4
5
6
7
8class Jumbo_Packet;
const int max_size = 9 * 1024; // 全局常量
byte payload [];
function new( int size );
payload = new[ size > max_size ? max_size : size ];
endfunction
endclass
实例常量在声明时不包含初始值,仅包含 const 限定符。这类常量可以在运行时赋值,但赋值只能在对应的类构造函数中执行一次。(有点类似于 C++ 中的 static readonly)1
2
3
4
5
6
7
8
9class Big_Packet;
const int size; // 实例常量
byte payload [];
function new();
size = $urandom % 4096; // 在 new 中赋值一次 -> 允许
payload = new[ size ];
endfunction
endclass
通常,全局常量也会被声明为 static,因为它们对于类的所有实例都是相同的。然而,实例常量不能被声明为 static,因为这样做会禁止在构造函数中进行任何赋值。
虚方法
类中的方法可通过关键字 virtual 标识。虚方法是实现多态性的基础结构。虚方法必须覆盖其所有基类中的同名方法,而非虚方法仅覆盖该类及其派生类中的方法。一种理解方式是:每个类层次结构中,虚方法仅有一个实现,且始终位于最新派生的类中。虚方法为后续覆盖它们的方法提供了原型,即通常包含方法声明首行的所有信息:封装准则、参数类型与数量,以及需要时的返回类型。
子类中的虚方法覆盖必须具有匹配的参数类型、相同的参数名称、相同的限定符以及与原型一致的方向。在派生类的方法声明中,virtual 限定符是可选的。虚函数的返回类型应为以下之一:
- 与超类中虚函数返回类型匹配的类型
超类虚函数返回类型的派生类类型。
默认表达式无需完全匹配,但默认值的存在与否必须一致。
- 当从构造函数
new()中调用virtual方法时,须注意类属性初始化顺序,因为该方法所引用的属性可能尚未初始化,具体取决于该方法是从构造函数链中的哪个位置调用的。 - 虚方法可以覆盖非虚方法,但一旦某个方法被标识为虚方法,则在其任何子类中重写该方法时,它必须保持虚方法的性质。在这种情况下,后续声明中可以使用
virtual关键字,但并非强制要求。
1 | |
抽象类与纯虚方法
可以创建一组类,这些类可被视为均派生自一个共同的基类。例如,一个类型为 BasePacket 的公共基类定义了数据包的结构,但其本身并不完整,因此永远不会被实例化。这类基类被称为抽象类。然而,从这个抽象基类可以派生出多个有用的子类,它们看起来非常相似,都需要相同的方法集,但其内部细节可能存在显著差异。
通过使用关键字 virtual 标识,可以将基类定义为抽象类:1
2
3virtual class BasePacket;
...
endclass
- 抽象类的对象不能直接实例化。其构造函数只能通过从非抽象扩展对象开始的构造函数调用链间接调用。
- 抽象类中的虚方法可以声明为原型而不提供具体实现。这被称为纯虚方法,需使用关键字
pure标识,且不提供方法体 - 扩展子类可以通过提供方法体的虚方法重写纯虚方法来实现具体功能
- 抽象类可以进一步扩展为其他抽象类,但所有纯虚方法必须被重写实现后,才能被非抽象类扩展
- 当类中所有方法均具有实现时,该类才是完整的,此时方可被实例化
- 任何类都可以扩展为抽象类,并可以添加额外的纯虚方法或重写已有的纯虚方法。
示例:没有语句体的方法仍然是合法且可调用的方法。例如,若函数1
2
3
4
5
6
7
8
9
10virtual class BasePacket;
pure virtual function integer send(bit[31:0] data); // 无具体实现
endclass
class EtherPacket extends BasePacket;
virtual function integer send(bit[31:0] data);
// 函数具体实现
...
endfunction
endclasssend声明如下,则其具有实现:1
2virtual function integer send(bit[31:0] data); // 将返回 'x
endfunction
多态性:动态方法查找
多态性允许使用超类类型的变量来持有子类对象,并直接从超类变量引用这些子类的方法。例如,假设数据包对象的基类 BasePacket 将其所有子类通常使用的公共方法定义为虚函数。这些方法包括发送、接收和打印。尽管 BasePacket 是抽象的,但仍可用于声明变量:1
BasePacket packets[100];
现在,可以创建各种数据包对象的实例并将其放入数组中:1
2
3
4
5
6EtherPacket ep = new; // 继承自 BasePacket
TokenPacket tp = new; // 继承自 BasePacket
GPSPacket gp = new; // 继承自 EtherPacket
packets[0] = ep;
packets[1] = tp;
packets[2] = gp;
如果数据类型是整数、位或字符串等,所有这些类型都无法存储到单个数组中,但通过多态性,这成为可能。在本例中,由于方法被声明为虚函数,即使编译器在编译时不知道将加载什么内容,仍可通过超类变量访问适当的子类方法。
例如,packets[1].send(); 将调用与 TokenPacket 类关联的发送方法。在运行时,系统会正确绑定来自相应类的方法。
类作用域解析运算符
类作用域解析运算符 :: 用于指定在类作用域内定义的标识符,其形式如下:1
class_type :: { class_type :: } identifier
作用域解析运算符 :: 的左操作数应为类类型名、包名、覆盖组类型名、覆盖点名、交叉点名、类型定义名或类型参数名。当使用类型名时,该名称在编译解析后应指向类或覆盖组类型。
由于类与其他作用域可能包含相同标识符,类作用域解析运算符能够唯一标识特定类的成员、参数或局部参数。除了消除类作用域标识符的二义性外,:: 运算符还支持从类外部访问静态成员(类属性和方法)、类参数及类局部参数,并允许在派生类中访问超类的公共或受保护元素。类参数或局部参数属于类的公共元素,而类作用域内的参数或局部参数属于常量表达式。1
2
3
4
5
6
7
8
9class Base;
typedef enum {bin,oct,dec,hex} radix;
static task print( radix r, integer n ); ... endtask
endclass
...
Base b = new;
int bin = 123;
b.print( Base::bin, bin );
Base::print( Base::hex, 66 );
类作用域解析运算符适用于类的所有静态元素:静态类属性、静态方法、类型定义、枚举、参数、局部参数、约束、结构体、联合体以及嵌套类声明。类作用域解析表达式可被读取(在表达式中)、写入(在赋值或子程序调用中)或触发(在事件表达式中)。类作用域也可用作类型前缀或方法调用的前缀。
与模块类似,类作为作用域可以嵌套。嵌套机制能够隐藏局部名称并实现资源的局部分配,这在需要为类实现部分功能而定义新类型时尤为实用。在类内部声明类型有助于避免命名冲突,并防止仅被该类使用的符号污染外部作用域。需要注意的是,嵌套在类作用域内的类型声明是公开的,可以在类外部进行访问。1
2
3
4
5
6
7
8
9
10
11
12
13
14class StringList;
class Node; // 链表节点的嵌套类
string name;
Node link;
endclass
endclass
class StringTree;
class Node; // 二叉树节点的嵌套类
string name;
Node left, right;
endclass
endclass
// StringList::Node 与 StringTree::Node 是不同的
类作用域解析运算符支持以下功能:
- 从类层次结构外部访问静态公共成员(方法和类属性)
- 在派生类内部访问超类的公共或受保护类成员
- 从类层次结构外部或派生类内部访问类内声明的约束、类型声明和枚举命名常量
- 从类层次结构外部或派生类内部访问类内声明的参数和局部参数
嵌套类应具有与包含类中方法相同的访问权限。它们对包含类的局部和受保护方法及属性拥有完全访问权限。嵌套类在词法作用域内可无限制地访问包含类的静态属性、方法、参数及局部参数。除非通过传递给它的句柄或其他可访问的句柄,否则它们不能隐式访问非静态属性和方法。对于外部类不存在隐式的 this 句柄。例如:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16class Outer;
int outerProp;
local int outerLocalProp;
static int outerStaticProp;
static local int outerLocalStaticProp;
class Inner;
function void innerMethod(Outer h);
outerStaticProp = 0; // 合法,与 Outer::outerStaticProp 相同
outerLocalStaticProp = 0; // 合法,嵌套类可以访问包含类的 local 成员
outerProp = 0; // 不合法,没有包含类的实例,不能访问非 static 成员
h.outerProp = 0; // 合法,有实例可以访问公共成员
h.outerLocalProp = 0; // 合法,嵌套类可以访问非静态的 local 成员
endfunction
endclass
endclass
块外声明
将方法定义移至类声明体外通常更为便捷。这一过程分为两步:
- 首先,在类体内声明方法原型,即明确其为函数或任务、任何限定符(如
local、protected或virtual),以及完整的参数规范并附加extern限定符。extern限定符表明该方法的主体(即其实现)将在类声明之外定义。 - 其次,在类声明外部声明完整的方法(例如保留原型但去除限定符),并通过类名和双冒号限定方法名称,以将其与所属类关联。
1
2
3
4
5
6
7
8
9
10
11
12
13class Packet;
Packet next;
function Packet get_next(); // 单行声明
get_next = next;
endfunction
// 外部(extern)声明
extern protected virtual function int send(int value);
endclass
function int Packet::send(int value); // 去除 protected virtual,添加 Packet::
// 方法主体
...
endfunction
块外方法声明必须与原型声明完全一致,但以下情况除外:
- 方法名称前需添加类名及类作用域解析运算符
- 如后续说明所述,函数返回类型在块外声明中可能也需要添加类作用域限定
原型中指定的默认参数值在块外声明中可以省略
若在块外声明中指定了默认参数值,则原型中必须存在语法完全相同的默认参数值声明
- 块外声明应声明在与类声明相同的作用域内,并且应位于类声明之后
- 若为某个特定的外部方法提供多个块外声明,则视为错误
- 在某些情况下,需要使用类作用域解析运算符来命名具有块外声明的方法的返回类型
- 当块外声明的返回类型在类内部定义时,应使用类作用域解析运算符来指示内部返回类型
1 | |
块外方法声明应能访问声明其对应原型所在类的所有声明。遵循常规解析规则,原型仅当类类型在其之前声明时才能访问它们。若原型中引用的标识符解析结果与块外方法声明头部对应标识符解析的声明不一致,则视为错误。1
2
3
4
5
6
7
8typedef int T;
class C;
extern function void f(T x); // 此处的标识符 T 解析为外部作用域中的 T 声明
typedef real T;
endclass
function void C::f(T x); // 此处的 T 解析为 C::T,不匹配,应当报告错误
endfunction
参数化类
定义一种泛型类通常很有用,其实例化对象可以具有不同的数组大小或数据类型。这避免了为每种大小或类型编写相似的代码,并允许使用单一规范来创建本质上不同且不可互换的对象。
SystemVerilog 的参数机制可用于对类进行参数化:1
2
3class vector #(int size = 1);
bit [size-1:0] a;
endclass
随后可以像模块或接口一样实例化该类的对象:1
2
3vector #(10) vten; // 包含大小为 10 的向量的对象
vector #(.size(2)) vtwo; // 包含大小为 2 的向量的对象
typedef vector#(4) Vfour; // 包含大小为 4 的向量的类
当使用类型作为参数时,此功能尤其有用:1
2
3
4
5class stack #(type T = int);
local T items[];
task push( T a ); ... endtask
task pop( ref T a ); ... endtask
endclass
上述类定义了一个泛型栈类,可以用任意类型进行实例化:1
2
3stack is; // 默认:整数栈
stack#(bit[1:10]) bs; // 10 位向量的栈
stack#(real) rs; // 实数栈
任何类型都可以作为参数提供,包括用户定义的类型(如类或结构体)。
泛型类与实际参数值的组合称为特化。类的每个特化都拥有一组独立的静态成员变量。若要在多个类特化之间共享静态成员变量,应将其放置在非参数化的基类中。1
2
3
4
5
6
7
8class vector #(int size = 1);
bit [size-1:0] a;
static int count = 0;
function void disp_count();
$display( "count: %d of size %d", count, size );
endfunction
endclass
上述示例中的变量 count 只能通过对应的 disp_count 方法访问。类 vector 的每个特化都有其独立的 count 副本。
特化是指特定泛型类与一组唯一参数的组合。当满足以下条件时,参数看作是相同的,特化的类也相同:
- 参数为类型参数,且两种类型匹配。
- 参数为值参数,且其类型和值均相同。
特定泛型类的所有匹配特化必须表示相同的类型。泛型类的匹配特化集合由其类声明所在的上下文定义。由于包中的泛型类在整个系统中可见,因此包泛型类的所有匹配特化属于同一类型。在其他上下文(如模块或程序)中,包含泛型类声明的作用域的每个实例都会创建一个唯一的泛型类,从而定义一组新的匹配特化。
泛型类本身不是类型,只有具体特化才表示类型。在前述示例中,类 vector 仅在应用参数后才成为具体类型,例如:1
2typedef vector my_vector; // 使用默认大小 1
vector#(6) vx; // 使用大小 6
为避免在声明中重复特化或创建该类型的参数,应使用 typedef:1
2
3typedef vector#(4) Vfour;
typedef stack#(Vfour) Stack4;
Stack4 s1, s2; // 声明 Stack4 类型的对象
参数化类可以扩展另一个参数化类。例如:1
2
3
4
5class C #(type T = bit); ... endclass // 基类
class D1 #(type P = real) extends C; // T 为 bit(默认值)
class D2 #(type P = real) extends C #(integer); // T 为 integer
class D3 #(type P = real) extends C #(P); // T 为 P
class D4 #(type P = C#(real)) extends P; // 默认情况下 T 为 real
类 D1 使用基类的默认类型参数(bit)扩展基类 C。类 D2 使用整数参数扩展基类 C。类 D3 使用扩展类参数化的类型参数(P)扩展基类 C。类 D4 扩展由类型参数 P 指定的基类。
当类型参数或 typedef 名称用作基类时(如上述类 D4),该名称必须在细化后解析为类类型。
参数化类的默认特化是指使用空参数覆盖列表对参数化类进行的特化。对于参数化类 C,默认特化为 C#()。除了作为作用域解析运算符的前缀外,使用参数化类的未修饰名称应表示该类的默认特化。并非所有参数化类都具有默认特化,因为类不提供参数默认值是合法的。在这种情况下,所有特化必须至少覆盖那些没有默认值的参数。1
2
3
4
5
6
7
8
9
10class C #(int p = 1);
...
endclass
class D #(int p);
...
endclass
C obj; // 合法;等价于 "C#() obj"
D obj; // 非法;D 没有默认特化
参数化类的类作用域解析运算符
对于参数化类,若类作用域解析运算符的前缀是该参数化类的无修饰名称,则其使用应仅限于该命名参数化类的作用域内及其块外声明中。在此类情况下,参数化类的无修饰名称并不表示默认特化,而是用于明确引用该参数化类的成员。若需将默认特化作为类作用域解析运算符的前缀,必须使用显式默认特化形式 #()。
在参数化类或其块外声明的上下文之外,类作用域解析运算符可用于访问该类的任意参数。在此类上下文中,必须使用显式特化形式;参数化类的无修饰名称应视为非法。显式特化形式可表示特定参数或默认特化形式。类作用域解析运算符可访问局部参数或类参数中的值参数与类型参数。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18class C #(int p = 1);
parameter int q = 5; // local 参数
static task t;
int p;
int x = C::p; // C::p 和 p 不同
endtask
endclass
int x = C::p; // 非法;在此上下文中不允许使用 C::
int y = C#()::p; // 合法;指向默认特化中参数 p
typedef C T; // T 是默认特化,而非名称 "C" 的别名
int z = T::p; // 合法;T::p 指向默认特化中的 p
int v = C#(3)::p; // 合法;C#(3) 特化中的参数 p
int w = C#()::q; // 合法;指向局部参数
T obj = new();
int u = obj.q; // 合法;指向局部参数
bit arr[obj.q]; // 非法:局部参数不是常量表达式
在参数化类方法的块外声明中,使用类作用域解析运算符应被视为在参数化类内部对名称的引用,并不暗示任何特化。1
2
3
4
5
6
7
8
9class C #(int p = 1, type T = int);
extern static function T f();
endclass
function C::T C::f();
return p + C::p;
endfunction
initial $display("%0d %0d", C#()::f(),C#(5)::f()); // 输出 "2 10"
接口类
(Todo)
类型定义类
有时需要在类本身声明之前声明类变量;例如,当两个类需要相互持有对方的句柄时。在编译器处理第一个类的声明过程中,若遇到对第二个类的引用,此时该引用尚未定义,编译器会将其标记为错误。
此问题可通过使用 typedef 为第二个类提供前向声明来解决:1
2
3
4
5
6
7
8
9typedef class C2; // C2 被声明为类类型
class C1;
C2 c;
endclass
class C2;
C1 c;
endclass
在此示例中,C2 被声明为类类型,这一事实在源代码后续部分得到确认。类构造始终会创建类型,无需为此目的使用 typedef 声明(例如 typedef class …)。
- 语句
typedef class C2;中的class关键字并非必需,仅用于文档说明。语句typedef C2;具有同等效果且工作方式完全相同。 - 前向类声明的实际类定义必须在相同局部作用域或生成块内完成解析。
- 类的前向类型定义可引用带参数端口列表的类。
1 | |
第七章 进程(always/initial)
在仿真开始时,初始过程(initial)与持续过程(always)即被激活。初始过程仅执行一次,其活动在语句执行完毕后终止。持续过程会重复执行,其活动仅在仿真终止时结束。初始过程与持续过程之间不存在隐含的执行顺序,初始过程无需安排在持续过程之前调度执行。模块中定义的初始过程与持续过程的数量没有限制。最终过程(final)在仿真时间结束时激活,且仅执行一次。任务(task)与函数(function)是通过其他过程中的一个或多个位置调用的过程,具体描述见第十一章 任务与函数(子程序)。
初始过程(initial)
初始过程仅执行一次,其活动在语句执行完毕后即终止。以下示例展示了在仿真开始时使用初始过程对变量进行初始化的方法:1
2
3
4
5initial begin
a = 0; // 初始化 a
for (int index = 0; index < size; index++)
memory[index] = 0; // 初始化存储器字
end
初始过程的另一个典型用途是描述波形生成,这些波形仅执行一次,为被仿真电路的主体部分提供激励信号:1
2
3
4
5
6
7initial begin
inputs = 'b000000; // 在零时刻初始化
#10 inputs = 'b011001; // 第一种模式
#10 inputs = 'b011011; // 第二种模式
#10 inputs = 'b011000; // 第三种模式
#10 inputs = 'b001000; // 最后一种模式
end
最终过程(final)
最终过程类似于初始过程,用于定义一个语句过程块,不同之处在于它在仿真时间结束时执行且无延迟。最终过程通常用于显示仿真的统计信息。最终过程内部允许的语句仅限于函数声明中允许的语句,以确保它们在一个仿真周期内执行。与初始过程不同,最终过程不作为独立进程执行,而是在零时间内以单个进程的一系列函数调用的形式执行。所有最终过程应按任意顺序执行。在所有最终过程执行完毕后,不应再执行任何已调度的事件。
当仿真因显式或隐式调用 $finish 而结束时,最终过程将执行。例如:1
2
3
4final begin
$display("执行的周期数 %d", $time/period);
$display("最终程序计数器 = %h", PC);
end
- 若在最终过程中执行
$finish、tf_dofinish()或vpi_control(vpiFinish,...),仿真将立即结束。 - 最终过程在单次仿真中仅能触发一次。
- 最终过程应在任何表示仿真结束的PLI回调之前执行。
- 最终过程按任意但确定的顺序执行。
持续过程(always)
持续过程共有四种形式:always、always_comb、always_latch 和 always_ff。所有形式的持续过程都会在仿真期间持续重复执行。
通用 always 过程
always 关键字表示通用持续过程,可用于描述重复性行为(例如时钟振荡器),也可结合适当的时序控制,用于表示组合逻辑、锁存器和时序硬件行为。
由于通用 always 过程具有循环特性,仅在与某种时序控制结合使用时才具有实际意义。若 always 过程未设置仿真时间推进控制,将导致仿真死锁。1
always #half_period areg = ~areg;
组合逻辑 always_comb 过程
SystemVerilog 为组合逻辑行为建模提供了专用的 always_comb 过程。例如:1
2
3
4always_comb
a = b & c;
always_comb
d <= #1ns b & c;
always_comb 过程具有与通用 always 过程不同的功能,具体如下:
- 存在一个隐式敏感列表
- 赋值左侧的变量不得被任何其他过程写入。但允许对变量的独立元素进行多次赋值,只要它们的最长静态前缀不重叠
- 该过程会在时间零点自动触发一次,且在所有 initial 和 always 过程启动之后执行,以确保过程的输出与输入保持一致。
- 若 always_comb 过程中的行为不表示组合逻辑,则发出警告
always_comb 的隐式敏感列表包括:
- 在过程块内或块内调用的任何函数中读取的每个变量或选择表达式的最长静态前缀的展开式,但以下情况除外:
- 在过程块内或块内调用的任何函数中声明的变量的任何展开式;
- 在过程块内或块内调用的任何函数中同时被写入的任何表达式。
层次化函数调用和来自包(package)的函数调用均被视为普通函数进行分析,使用类作用域解析运算符引用的静态方法函数调用也是如此。对类对象的引用和类对象的方法调用不会向 always_comb 的敏感列表添加任何内容,除非传递给这些方法调用的参数表达式本身具有敏感项贡献。
always_comb 中允许任务调用,但任务的内容不会向敏感列表添加任何内容。
注:不消耗时间的任务可以用 void 函数替代,以便对其内容进行敏感项分析。
在过程中使用的立即断言内,或在过程中调用的任何函数内使用的表达式,会贡献给 always_comb 的隐式敏感列表,就像该表达式被用作 if 语句的条件一样。断言动作块中使用的表达式不会贡献给 always_comb 的隐式敏感列表。
always_comb 与 always @* 的比较
always_comb会在仿真零时刻自动执行一次,而always @*需等待推断出的敏感列表中的信号发生变化才会触发。always_comb对函数内部内容的变化敏感,而always @*仅对函数参数的变化敏感。- 在
always_comb过程中,赋值语句左侧的变量(包括被调用函数内部的变量)不允许被其他任何进程写入,而always @*允许多个进程写入同一变量。 always_comb中的语句不得包含阻塞性语句、具有阻塞时序或事件控制的语句,或 fork-join 语句。always_comb对过程内及过程所调用函数内即时断言中的表达式敏感,而always @*仅对过程内即时断言中的表达式敏感。
锁存逻辑 always_latch 过程
SystemVerilog 还提供了一种特殊的 always_latch 过程,用于建模锁存逻辑行为。例如:1
2always_latch
if(ck) q <= d;
always_latch 结构与 always_comb 结构完全相同,只是软件工具应执行额外检查,并在 always_latch 结构中的行为不表示锁存逻辑时发出警告;组合逻辑过程中的所有规定均适用于 always_latch。
时序逻辑 always_ff 过程
always_ff 过程可用于建模可综合的时序逻辑行为。例如:1
2
3
4always_ff @(posedge clock iff reset == 0 or posedge reset) begin
r1 <= reset ? 0 : r2 + 1;
...
end
always_ff 过程强制要求其包含且仅包含一个事件控制,且不允许使用阻塞时序控制。在 always_ff 过程中赋值语句左侧的变量(包括被调用函数中的变量)不得被任何其他过程写入。软件工具执行额外检查,并在 always_ff 过程中的行为不表示时序逻辑时发出警告。
块语句
块语句是一种将多条语句组合在一起的方式,使其在语法上如同单条语句般运作。块语句主要分为以下两类:
- 顺序块,也称为 begin-end 块。顺序块由关键字 begin 和 end 界定。顺序块中的过程语句将按照给定的顺序依次执行。
- 并行块,也称为 fork-join 块。并行块由关键字 fork 与 join、join_any 或 join_none 共同界定。并行块中的过程语句将并发执行。
顺序块
顺序块具有以下特性:
- 语句按顺序依次执行。
- 每条语句的延迟值均相对于前一条语句执行的仿真时间进行计算。
- 控制流程将在最后一条语句执行完毕后退出该块。
并发块
fork-join 并行块结构能够从其每个并行语句中创建并发进程。并行块应具备以下特性:
- 各语句应并发执行
- 每个语句的延迟值应相对于进入该块的仿真时间进行计算
- 延迟控制可用于为赋值操作提供时间顺序
- 当基于 join 关键字类型的最后一个按时间顺序执行的语句完成后,控制将退出该块
- 在函数调用内部有受限的使用
SystemVerilog 为指定父进程(派生进程)何时恢复执行提供了三种选项:
| 选项 | join类型 | 描述 |
|---|---|---|
| join | 所有进程完成 | 父进程阻塞,直到此 fork 派生的所有进程完成 |
| join_any | 任一进程完成 | 父进程阻塞,直到此 fork 派生的任一进程完成 |
| join_none | 无阻塞 | 父进程与 fork 派生的所有进程并发执行。派生进程需等待父线程执行阻塞语句或终止后才开始执行。 |
在 fork-join 块上下文中使用 return 语句是非法的,将导致编译错误。例如:1
2
3
4
5
6task wait_20;
fork
#20;
return; // 非法:不能使用return;任务存在于另一个进程中
join_none
endtask
- 在 fork-join 块的 block_item_declaration 中声明的变量,每当执行进入其作用域时,都应在任何进程启动之前初始化为其初始化值表达式。
- 在 fork-join_any 或 fork-join_none 块中,除了在 fork 的 block_item_declaration 声明的变量的初始化值表达式中,引用通过引用传递的形式参数是非法的。这些变量在循环结构生成的进程中非常有用,用于存储每次迭代的唯一数据。上述示例将输出123。
1
2
3
4
5
6
7
8
9
10initial
for( int j = 1; j <= 3; ++j )
fork
automatic int k = j; // 每个 j 值的本地副本 k
#k $write( "%0d", k );
begin
automatic int m = j; // m 的值是不确定的
...
end
join_none
过程时序控制
SystemVerilog 提供了两种显式的时序控制方式,用于决定过程语句何时执行。
第一种是延时控制,通过表达式指定从首次遇到该语句到实际执行之间的时间间隔。延时表达式可以是电路状态的动态函数,也可以是一个简单的数值,用于在时间上分隔语句的执行。延时控制在描述激励波形时尤为重要。
第二种时序控制是事件表达式,它允许将语句的执行延迟到某个仿真事件发生之后,该事件可能在与当前过程并发执行的其他过程中产生。仿真事件可以是线网或变量值的变化(隐式事件),也可以是由其他过程触发的显式命名事件(显式事件)。最常见的事件控制是对时钟信号上升沿或下降沿的响应。
仿真时间可通过以下三种方式之一向前推进:
- 延时控制(由符号
#引入) - 事件控制(由符号
@引入) - wait 语句(其功能类似于事件控制与 while 循环的结合)
有一类特殊的时序控制,仅允许在时钟块或者断言块中使用,由符号 ## 引入。
延时控制
延时控制后的过程语句相对于延时控制前的过程语句,其执行将延迟指定的时间。
- 若延迟表达式的计算结果为未知值或高阻值,则将其解释为零延迟。
- 若延迟表达式的计算结果为负值,则将其解释为与时间变量相同大小(64比特)的二进制补码无符号整数。
- 延迟表达式中允许使用指定参数,这些参数可通过 SDF 标注进行覆盖,此时表达式将重新计算。
1
2
3
4#10 rega = regb; // 将赋值语句的执行延迟 10 个时间单位:
#d rega = regb; // d 被定义为参数
#((d+e)/2) rega = regb; // 延迟时间为 d 和 e 的平均值
#regr regr = regr + 1; // 延迟时间为 regr 中的值
事件控制
过程语句的执行可以与线网或变量的值变化或声明事件的发生同步。线网和变量的值变化可用作触发语句执行的事件,这被称为检测隐式事件。事件也可以基于变化的方向,即向值 1(上升沿)或向值 0(下降沿)的变化。上升沿和下降沿事件的行为如下表所示,具体描述如下:
- 下降沿应在从 1 到 x、z 或 0 的转换中,以及从 x 或 z 到 0 的转换中被检测到
- 上升沿应在从 0 到 x、z 或 1 的转换中,以及从 x 或 z 到 1 的转换中被检测到
| 原值\变化值 | 0 | 1 | x | z |
|---|---|---|---|---|
| 0 | 无 | 上升沿 | 上升沿 | 上升沿 |
| 1 | 下降沿 | 无 | 下降沿 | 下降沿 |
| x | 下降沿 | 上升沿 | 无 | 无 |
| z | 下降沿 | 上升沿 | 无 | 无 |
除了上升沿(posedge)和下降沿(negedge)之外,还有第三种边沿事件——边沿(edge)——表示信号向 1 或 0 的任何变化。更精确地说,边沿事件的行为可以描述为:每当检测到下降沿或上升沿时,都应检测到一个边沿。
- 表达式的值发生任何变化时,都应检测到一个隐式事件。
- 边沿事件仅在表达式的最低位(LSB)上被检测。
- 表达式中任何操作数的值发生变化,但表达式结果未发生变化时,不应被检测为事件。
1 | |
- 如果表达式表示一个时钟块输入或双向端口,事件控制操作符将使用同步值,即由时钟事件采样的值。
- 表达式也可以表示一个时钟块名称(不带边沿限定符),由时钟事件触发。
- 用于事件控制的变量可以是任何整数数据类型或字符串类型。变量可以是简单变量或引用参数(通过引用传递的变量);它可以是数组、关联数组或上述类型的对象(类实例)的成员。
- 事件表达式应返回单数值。只要表达式最终简化为单数值,聚合类型可以在表达式中使用。对象成员或聚合元素可以是任何类型,只要表达式的结果是单数值即可。
- 如果事件表达式是对简单对象句柄或 chandle 变量的引用,当对该变量的写入操作导致其值与先前值不同时,将创建一个事件。
- 只要返回值的类型是单一的,并且方法被定义为函数而非任务,那么在事件控制表达式中允许使用对象的非虚方法以及聚合类型的内置方法或系统函数。
- 当方法或函数所引用的对象数据成员、聚合元素或动态大小数组的尺寸发生变化时,事件表达式会被重新求值。
事件或运算符
任意数量事件的逻辑或运算可以表示为:只要其中任一事件发生,就会触发后续过程语句的执行。关键字 or 或逗号字符(,)可用作事件的逻辑或运算符。在同一事件表达式中可以混合使用这两种形式。以逗号分隔的敏感列表应与以 or 分隔的敏感列表同义。1
2@(trig or enable) rega = regb; // 由 trig 或 enable 控制
@(posedge clk_a or posedge clk_b or trig) rega = regb;
以下示例展示了逗号(,)作为事件逻辑或运算符的用法:1
2
3always @(a, b, c, d, e)
always @(posedge clk, negedge rstn)
always @(a or b, c, d or e)
隐式事件表达式列表
事件控制中不完整的事件表达式列表是寄存器传输级(RTL)仿真中常见的错误来源。隐式事件表达式 @* 是一种便捷的简写形式,它通过将过程时序控制语句(可以是语句组)读取的所有线网和变量添加到事件表达式中,从而消除了这些问题。
- 在 always 过程开头用作敏感列表时,推荐使用 always_comb 过程,而非隐式事件表达式列表
@*。 - 出现在语句中的所有线网标识符和变量标识符将自动添加到事件表达式中,但以下情况除外:
- 仅出现在等待(wait)或事件(event)表达式中的标识符。
- 仅在赋值语句左侧的变量左值(variable_lvalue)中以层次化变量标识符(hierarchical_variable_identifier)形式出现的标识符。
根据这些规则,以下情况中的线网和变量均应被包含:
- 出现在赋值语句右侧的标识符;
- 出现在子程序调用中的标识符;
- 出现在 case 表达式和条件表达式中的标识符;
- 在赋值语句左侧作为索引变量的标识符;
- 在 case 项表达式中作为变量的标识符。
周期延迟控制
## 运算符可用于通过指定数量的时钟事件或时钟周期来延迟执行。该运算符后的表达式可以是任何计算结果为正整数的SystemVerilog表达式。周期的定义由当前生效的默认时钟块/当前断言块决定。若当前模块、接口、检查器或程序中未指定默认时钟块,编译器将报错。1
2##5; // 使用默认时钟块等待5个周期(时钟事件)
##(j + 1); // 使用默认时钟块等待j+1个周期(时钟事件)
周期延迟时序控制将等待指定次数的时钟事件。这意味着对于在仿真时间点未与关联时钟事件重合时执行的 ##1 语句,调用进程将延迟关联时钟周期的部分时间。##0周期延迟具有特殊处理规则:若当前时间步内尚未发生时钟事件,##0 周期延迟将挂起调用进程直至时钟事件发生;若进程执行 ##0 延迟时关联时钟事件已在当前时间步内发生,则进程将继续执行而不挂起。在同步驱动的右侧使用时,##0 周期延迟不产生任何效果,如同不存在该延迟。
周期延迟时序控制不可用于阻塞或非阻塞赋值语句中的赋值内延迟。
条件事件控制
@ 事件控制可以带有 iff 限定符。1
2
3
4module latch (output logic [31:0] y, input [31:0] a, input enable);
always @(a iff enable == 1)
y <= a; //锁存器处于透明模式
endmodule
事件表达式仅在 iff 后的条件为真时触发
- 此类表达式的求值发生在 a 变化时,而非 enable 变化时
- 在此类类似的事件表达式中,
iff的优先级高于or
序列事件
序列实例可用于事件表达式中,以基于序列的成功匹配来控制过程语句的执行。这使得命名序列的终点能够在其他进程中触发多个动作。序列实例可直接用于事件表达式中。当在事件表达式中指定序列实例时,执行事件控制的进程将阻塞,直到指定序列到达其终点。进程将在检测到终点的观察区域后恢复执行。1
2
3
4
5
6
7
8
9
10sequence abc;
@(posedge clk) a ##1 b ##1 c;
endsequence
program test;
initial begin
@ abc $display("Saw a-b-c");
L1: ...
end
endprogram
在上述示例中,当命名序列 abc 到达其终点时,程序块 test 中的初始过程解除阻塞,随后显示字符串 “Saw a-b-c”,并继续执行标签为 L1 的语句。在这种情况下,序列的终点充当了解除事件阻塞的触发器。
用于事件控制的序列会被实例化(类似于通过 assert property 语句实现);事件控制用于同步到序列的终点,而无论其起始时间如何。这些序列的参数必须是静态的;若将自动变量用作序列参数,将导致错误。
电平敏感事件控制
过程语句的执行可以延迟到某个条件变为真时再进行。这可以通过使用等待(wait)语句来实现,它是事件控制的一种特殊形式。等待语句的本质是电平敏感的,这与基本事件控制(由 @ 字符指定)的边缘敏感特性形成对比。等待语句将评估一个条件;如果该条件不成立,则等待语句后的过程语句将保持阻塞状态,直到该条件变为真才会继续执行。1
2
3
4begin
wait (!enable) #10 a = b;
#10 c = d;
end
如果进入该代码块时 enable 的值为 1,wait 语句将等待 enable 的值变为 0,再执行下一条语句(#10 a = b;)
如果进入 begin-end 代码块时 enable 已经为 0,则延迟 10 个单位时间后执行赋值语句 a = b;,且不会产生额外延迟。
电平敏感的序列控制
对于序列,可以等待序列终止状态为真再继续执行。这是通过使用电平敏感的等待语句与内置方法 triggered(该方法返回指定序列的当前结束状态)相结合来实现的。
如果给定序列在特定时间点(当前时间步长内)已达到其终点,则 triggered 序列方法会评估为真(1'b1),否则为假(1'b0)。
序列的触发状态在观察区域(Observed region)中设置,并在该时间步长的剩余时间内持续有效(即直到仿真时间推进)。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18sequence abc;
@(posedge clk) a ##1 b ##1 c;
endsequence
sequence de;
@(negedge clk) d ##[2:5] e;
endsequence
program check;
initial begin
wait( abc.triggered || de.triggered );
if( abc.triggered )
$display( "abc succeeded" );
if( de.triggered )
$display( "de succeeded" );
L2 : ...
end
endprogram
在前面的示例中,程序检查的初始过程会等待序列 abc 或序列 de 的结束点。当任一条件评估为真时,wait 语句会解除进程的阻塞,显示导致进程解除阻塞的序列,然后继续执行标记为L2的语句。
赋值内时序控制
赋值内延迟和事件控制包含在赋值语句内部,并以不同的方式修改活动流程。
- 赋值内延迟或事件控制应延迟将新值赋给左侧,但右侧表达式应在延迟之前进行计算
- 内部赋值延迟和事件控制既可用于阻塞赋值,也可用于非阻塞赋值
- 重复(repeat)事件控制应指定事件发生指定次数后的内部赋值延迟
- 若在评估时重复计数字面量或保存重复计数的有符号变量小于或等于 0,则赋值过程将如同不存在重复结构。
1 | |
| 使用赋值内时序控制 | 不使用赋值内时序控制 | ||||
|---|---|---|---|---|---|
|
|
||||
|
|
||||
|
|
在下面的例子中,data 会在第五个时钟上升沿来临时赋值给 a,注意 data 值在该语句执行时就被采样了。1
a <= repeat(5) @(posedge clk) data;
注意,此处的 repeat 只用于延时控制,不是循环语句。这个语句不能写成1
2a <= repeat(5) ( @(posedge clk) data ); // 语法错误
a <= repeat(5) begin @(posedge clk) data end; // 语法错误
进程控制语句
SystemVerilog 提供了多种结构,允许一个进程终止或等待其他进程完成。wait fork 结构用于等待进程执行完毕。disable 结构会停止指定命名块或任务内的所有活动,且不受父子关系限制(子进程可以终止父进程的执行,或一个进程可以终止无关进程的执行)。而 disable fork 结构在停止进程执行时会考虑父子关系的影响。
wait fork 语句
wait fork 语句会阻塞进程的执行流程,直到所有直接子进程(由当前进程创建的子进程,不包括它们的后代进程)完成执行。其语法如下:1
wait fork ;
当系统中不再有任何活动时,仿真会自动终止。当所有程序块执行完成时(即它们到达执行块的末尾),仿真也会自动终止,无论任何子进程的状态如何。wait fork 语句允许程序块在退出前等待其所有并发线程完成。
在以下示例中,调用任务 do_test 之前会生成两个直接子进程(child1 和 child2)。在任务 do_test 中,会生成另外三个直接子进程(child3、child4 和 child5)以及两个后代进程(descendant1 和 descendant2)。接着,函数 do_sequence 会生成另外两个直接子进程(child6 和 child7)。wait fork 语句会阻塞任务 do_test 的执行流程,直到所有七个直接子进程完成,然后才返回到其调用者。wait fork 语句并不直接依赖于由 child5 生成的后代进程。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27initial begin : test
fork
child1();
child2();
join_none
do_test();
end : test
task do_test();
fork
child3();
child4();
fork : child5 // 嵌套的 fork-join_none 是单个子进程
descendant1();
descendant2();
join_none
join_none
do_sequence();
wait fork; // 阻塞线程直到 child1 ... child7 完成
endtask
function void do_sequence();
fork
child6();
child7();
join_none
endfunction
disable 语句
disable 语句提供了终止与并发活动进程相关的活动的能力,同时保持了过程描述的结构化特性。该语句提供了一种机制,可以在任务执行完所有语句之前终止任务、跳出循环语句,或跳过语句以继续循环语句的下一次迭代。它适用于处理异常情况,例如硬件中断和全局复位。disable 语句还可用于终止带标签的语句的执行,包括延迟断言或过程并发断言。
disable 语句将终止任务或命名块的活动。执行将在该块之后或任务启动语句之后的语句处恢复。命名块或任务内启动的所有活动也将被终止。如果任务启动语句嵌套(即一个任务启动另一个任务,后者又启动其他任务),则禁用链中的某个任务将禁用该链下游的所有任务。如果一个任务被多次启动,则禁用该任务将终止其所有激活实例。
若任务被禁用,则以下由任务启动的活动结果将不确定:
- 传参方式为 output 和 inout 参数的结果
- 已调度但未执行的非阻塞赋值
- 过程连续赋值(assign 语句和 force 语句)
disable 语句可在块和任务内部使用,以禁用包含该语句的特定块或任务。该语句可用于禁用函数内的命名块,但不能用于禁用函数本身。若函数内的 disable 语句禁用了调用该函数的块或任务,则行为未定义。禁用自动任务或自动任务内的块时,其处理方式与常规任务的所有并发执行情况相同。
示例1:此示例演示了一个块如何禁用自身。1
2
3
4
5begin : block_name
rega = regb;
disable block_name;
regc = rega; // 此赋值永远不会执行
end
示例2:此示例展示了在命名块中使用 disable 语句,其作用类似于向前跳转的 goto 语句。执行 disable 语句后,接下来执行的语句是命名块之后的代码。1
2
3
4
5
6
7
8
9begin : block_name
...
...
if (a == 0)
disable block_name;
...
end // 命名块结束
// 继续执行命名块之后的代码
...
示例3:此示例演示了使用 disable 结构来终止不包含该语句的命名块的执行。如果该块当前正在执行,则控制权会跳转到该块之后的语句。如果该块是循环体,其行为类似于 continue。如果该块当前未执行,则disable语句无效。1
2
3
4
5
6
7
8
9
10
11
12
13
14module m (...);
always
begin : always1
...
t1: task1( ); // 任务调用
...
end
...
always
begin
...
disable m.always1; // 从头开始执行 always 内的 begin-end 块,注意 always 并没有被禁用
end
endmodule
disable fork 语句
disable fork 语句会终止调用进程的所有子进程及其子进程的后代。换句话说,如果任何子进程拥有自己的后代进程,禁用分支语句也会终止这些后代进程。
在以下示例中,任务 get_first 创建了三个等待特定设备(1、7 或 13)的任务实例。任务 wait_device 等待特定设备就绪,然后返回该设备的地址。当第一个设备就绪时,get_first 任务将恢复执行并终止仍在运行的 wait_device 进程。1
2
3
4
5
6
7
8task get_first( output int adr );
fork
wait_device( 1, adr );
wait_device( 7, adr );
wait_device( 13, adr );
join_any
disable fork;
endtask
disable fork 语句与普通 disable 语句的区别在于:disable fork 语句考虑进程的动态父子关系,而普通 disable 语句使用被禁用块的静态语法信息。因此,普通 disable 语句会终止执行特定块的所有进程(无论这些进程是否由调用线程创建),而禁用分支语句仅终止由调用线程创建的进程。
块别名
(Todo)
语句标签
(Todo)
第八章 赋值语句
第九章 运算符与表达式
表达式是一种将操作数与运算符结合起来的结构,用于产生一个结果,该结果取决于操作数的值以及运算符的语义含义。任何合法的操作数,例如线网位选择,即使没有任何运算符,也被视为一个表达式。在 SystemVerilog 语句中任何需要值的地方,都可以使用表达式。操作数可以是以下之一:
- 常量字面数字,包括实数字面量
- 字符串字面量
- 参数,包括局部参数和指定参数
- 参数位选择或部分选择,包括局部参数和指定参数
- 线网
- 线网位选择或部分选择
- 变量
- 变量位选择或部分选择
- 结构体,无论是紧凑结构体还是非紧凑结构体
- 结构体成员
- 紧凑结构体位选择或部分选择
- 联合体,包括紧凑、非紧凑或标记联合体
- 联合体成员
- 紧凑联合体位选择或部分选择
- 数组,无论是紧凑数组还是非紧凑数组
- 紧凑数组位选择、部分选择、元素或切片
- 非紧凑数组元素位选择或部分选择、元素或切片
- 调用用户自定义函数、系统定义函数或方法,返回上述任意类型
操作符
| 操作符 | 名称 | 操作数类型 |
|---|---|---|
= |
二元赋值运算符 | 任意 |
+= -= /= *= |
二元算术赋值运算符 | 整数、实数 |
%= |
二元算术模赋值运算符 | 整数 |
&= |= ^= |
二元位赋值运算符 | 整数 |
>>= <<= |
二元逻辑移位赋值运算符 | 整数 |
>>>= <<<= |
二元算术移位赋值运算符 | 整数 |
?: |
条件运算符 | 任意 |
+ - |
一元算术运算符 | 整数、实数 |
! |
一元逻辑非运算符 | 整数、实数 |
~ & ~& | ~| ^ ~^ ^~ |
一元逻辑归约运算符 | 整数 |
+ - * / ** |
二元算术运算符 | 整数、实数 |
% |
二元算术模运算符 | 整数 |
& | ^ ^~ ~^ |
二元位运算符 | 整数 |
>> << |
二元逻辑移位运算符 | 整数 |
>>> <<< |
二元算术移位运算符 | 整数 |
&& || –> <–> |
二元逻辑运算符 | 整数、实数 |
< <= > >= |
二元关系运算符 | 整数、实数 |
=== !== |
二元情况相等运算符 | 除实数外任意 |
== != |
二元逻辑相等运算符 | 任意 |
==? !=? |
二元通配相等运算符 | 整数 |
++ -- |
一元递增、递减运算符 | 整数、实数 |
inside |
二元集合成员运算符 | 左操作数的单数形式 |
dist |
二元分布运算符 | 整数 |
{} {{ }} |
连接、复制运算符 | 整数 |
{<<{}} {>>{}} |
流运算符 | 整数 |
操作符优先级顺序
| 操作符 | 关联性 | 优先级 |
|---|---|---|
() [] :: . |
左侧优先 | 16 |
+ - ! ~ & ~& | ~| ^ ~^ ^~ ++ --(一元) |
- | 15 |
** |
左侧优先 | 14 |
* / % |
左侧优先 | 13 |
+ - (二元) |
左侧优先 | 12 |
<< >> <<< >>> |
左侧优先 | 11 |
< <= > >= inside dist |
左侧优先 | 10 |
== != === !== ==? !=? |
左侧优先 | 9 |
& (二元) |
左侧优先 | 8 |
^ ~^ ^~ (二元) |
左侧优先 | 7 |
| (二元) |
左侧优先 | 6 |
&& |
左侧优先 | 5 |
|| |
左侧优先 | 4 |
?: |
右侧优先 | 3 |
–> <–> |
右侧优先 | 2 |
= += -= *= /= %= &= ^= |=<<= >>= <<<= >>>= := :/ <= |
- | 1 |
{} {{ }} |
- | 0 |
赋值运算符
除了简单的赋值运算符 = 外,SystemVerilog 还包含 C 语言的赋值运算符以及特殊的位运算赋值运算符:+=、-=、*=、/=、%=、&=、|=、^=、<<=、>>=、<<<= 和 >>>=。从语义上讲,赋值运算符等同于阻塞赋值,但区别在于左侧的任何索引表达式仅被计算一次。例如:1
a[i] += 2; // 等同于 a[i] = a[i] + 2;
自增与自减运算符
SystemVerilog 包含了 C 语言中的自增与自减赋值运算符:++i、--i、i++ 和 i--。在表达式中使用这些运算符时无需括号。这些自增与自减赋值运算符的行为类似于阻塞赋值。在表达式中,赋值操作相对于其他操作的顺序是未定义的。当变量在整型表达式内或其他实现无法保证求值顺序的上下文中同时被写入和读取(或写入)时,例如:1
2i = 10;
j = i++ + (i = i - 1);
执行后,j 的值可能是 18、19 或 20,具体取决于自增操作与赋值语句的相对顺序。
- 当自增与自减运算符应用于实数操作数时,操作数将增加或减少 1.0。
算术运算符
| 表达式 | 含义 |
|---|---|
a + b |
a 加 b |
a - b |
a 减 b |
a * b |
a 乘以 b(或 a 乘 b) |
a / b |
a 除以 b |
a % b |
a 取模 b |
a ** b |
a 的 b 次幂 |
- 整数除法应向零方向截断所有小数部分
- 对于除法或取模运算符,如果第二个操作数为零,则整个结果值应为 x
- 取模运算的结果符号应与第一个操作数的符号相同
- 如果幂运算符的任一操作数为实数,则结果类型应为实数
- 如果幂运算符第一个操作数为零且第二个操作数为非正数,或者第一个操作数为负数且第二个操作数不是整数值,则幂运算符的结果是未定义的。
- 如果幂运算符的两个操作数均不是实数,则结果类型(位宽按照Todo规则确定)
- 如果幂运算符第一个操作数为零且第二个操作数为负数,则结果值为 ‘x。如果第二个操作数为零,则结果值为 1。
- 在所有情况下,幂运算符的第二个操作数应被视为自确定的。
关系运算符
使用关系运算符 < <= > >= 的表达式,若指定的关系为假,则结果为标量值 0;若为真,则结果为值 1。若关系运算符的任一操作数包含未知值(x)或高阻值(z),则结果应为 1 位未知值(x)。
- 当关系表达式的一个或两个操作数为无符号数时,该表达式应解释为无符号值之间的比较。若操作数的位宽不等,则较小的操作数应进行零扩展至较大操作数的位宽。
- 当两个操作数均为有符号数时,该表达式应解释为有符号值之间的比较。若操作数的位宽不等,则较小的操作数应进行符号扩展至较大操作数的位宽。
- 若任一操作数为实数操作数,则另一操作数应转换为等效的实数值,且该表达式应解释为实数值之间的比较。
- 所有关系运算符具有相同的优先级。关系运算符的优先级低于算术运算符。
相等运算符
相等运算符逐位比较操作数。与关系运算符类似,若比较失败则结果为 0,成功则为 1。
| 表达式 | 含义 |
|---|---|
a === b |
a 等于 b,包括 x 和 z |
a !== b |
a 不等于 b,包括 x 和 z |
a == b |
a 等于 b,结果可以是未知 |
a != b |
a 不等于 b,结果可以是未知 |
- 所有四个相等运算符具有相同的优先级。
- 当一个或两个操作数为无符号数时,表达式应解释为无符号数值之间的比较。若操作数的位宽不等,则较短的操作数应进行零扩展至较长操作数的位宽。
- 当两个操作数均为有符号数时,表达式应解释为有符号数值之间的比较。若操作数的位宽不等,则较短的操作数应进行符号扩展至较长操作数的位宽。
- 若任一操作数为实数操作数,则另一操作数应转换为等效的实数值,且表达式应解释为实数值之间的比较。
- 若任一操作数为 chandle 类型或字面量
null,且其中一个操作数可赋值兼容于另一操作数,则逻辑相等(或全等)运算符为合法操作。运算符会比较类句柄、接口类句柄或 chandle 的值。 - 若任一操作数为 chandle 类型或字面量
null,逻辑相等(或全等)运算符亦为合法操作。运算符会比较类句柄、接口类句柄或 chandle 的值。 - 对于逻辑相等与逻辑不等运算符(
==和!=),若因操作数中存在未知或高阻态位而导致关系不确定,则结果应为 1 位未知值(x)。 - 对于全等与不全等运算符(
===和!==),其比较方式应与过程化 case 语句相同。x 或 z 位将参与比较,且必须完全匹配才被视为相等。这些运算符的结果始终为已知值,即 1 或 0。
通配相等运算符
| 表达式 | 说明 |
|---|---|
| a ==? b | a 等于 b,b 中的 x 和 z 值作为通配符处理 |
| a !=? b | a 不等于 b,b 中的 x 和 z 值作为通配符处理 |
- 通配相等运算符(
==?)和不等运算符(!=?)将其右操作数中特定位上的 x 和 z 值视为通配符。左操作数中的 x 和 z 值则不被视为通配符。 - 通配符位可以匹配左操作数中对应位的任意位值(0、1、z 或 x)。其余位的比较方式与逻辑相等和逻辑不等运算符相同。
- 如果通配相等/不等运算符的操作数位长不等,则操作数会按照与逻辑相等/不等运算符相同的方式进行扩展。
- 若关系为真,运算符返回 1;若关系为假,则返回 0;若关系未知,则返回 x。
==?和!=?运算符在左操作数包含 x 或 z,且右操作数对应位不是通配符时,可能返回 x。- 如果操作数是类句柄、接口类句柄、chandle 或字面量
null,通配相等运算符的行为与逻辑相等运算符等效。
逻辑运算符
(Todo)
位运算符
(Todo)
归约运算符
(Todo)
移位运算符
(Todo)
条件运算符
(Todo)
连接运算符
(Todo)
集合成员运算符
inside 运算符可用于查询集合元素匹配,运算符左侧的表达式为任意单一表达式,右侧的集合成员 open_range_list 由逗号分隔的表达式或范围列表构成。若列表中存在非紧凑数组,则通过向下遍历数组直至找到单一值来遍历其元素。集合成员将被扫描直至找到匹配项,此时操作返回 1’b1。若未找到匹配项,返回 1’b0。值可重复出现,因此值与值域可存在重叠。表达式与值域的求值顺序具有非确定性。1
2
3
4int a, b, c;
if ( a inside {b, c} ) ...
int array [$] = '{3,4,5};
if ( ex inside {1, 2, array} ) ... // 等同于 { 1, 2, 3, 4, 5}
- 非整数表达式使用相等运算符(
==)进行比较 - 整数表达式使用通配符等值运算符(
==?),使得集合中值的 x 或 z 位(对应右操作数)在该位位置被视为无关紧要 - 如果未找到匹配项,但某些比较结果为 x,则
inside运算符返回 1’bx - 返回值本质上是左侧表达式与集合中所有比较结果的或归约运算
1 | |
- 可以在
open_range_list里通过方括号[]指定一个范围,格式为[下限:上限]。 - 以
$指定的界限代表左侧表达式类型的最低值或最高值 - 指定范围时,表达式应为关系运算符(
<=、>=)可处理的单一类型 - 若冒号左侧界限大于右侧界限,则范围为空且不包含任何值
1
2
3
4bit ba = a inside { [16:23], [32:47] };
string I;
if (I inside {["a rock":"hard place"]}) ...
// I在"a rock"和"hard place"之间(按字典序)
流运算符
能够被打包成位流的数据类型称为位流类型。位流类型包括以下类型:
- 任何整数类型、紧凑类型或字符串类型
- 上述类型的非紧凑数组、结构体或类
- 上述任意类型的动态大小数组(动态数组、关联数组或队列)
该定义具有递归性,例如,一个包含 int 队列的结构体也属于位流类型。
流操作符能够将位流类型,按照用户指定的顺序打包为位序列。当用于左侧时,流操作符执行反向操作,即将位流解包为一个或多个变量。
- 若打包的数据包含任何四态类型,则打包操作的结果为四态流;否则,打包结果为二态流
- 流式拼接应作为赋值的目标、赋值的源、位流转换的操作数,或作为另一个流式拼接中的流表达式使用
- 若在表达式中将流式拼接作为操作数使用而未先将其转换为位流类型,则属于错误
- 当流式拼接作为赋值源时,赋值目标应为位流类型的数据对象或另一个流式拼接。
- 若目标为位流类型的数据对象,则源流式拼接生成的流在必要时需先进行扩展,以使其在目标中左对齐,具体规则如下:
- 若目标表示固定大小的变量,且其宽度(位数)小于流的宽度,则产生错误。
- 若目标表示固定大小的变量,且其宽度大于流的宽度,则通过在右侧填充零位将流扩展至与目标宽度匹配。
- 若目标表示动态大小的变量(如队列或动态数组),则首先调整变量大小,使其元素数量最小化且总宽度等于或大于流的宽度。若调整后的变量宽度大于流的宽度,则通过在右侧填充零位将流扩展至与目标宽度匹配。
- 根据上述规则扩展后的流(若需要)将隐式转换为目标的类型。
连接规则
在流连接中,每个流表达式(从最左侧开始,按逗号分隔的流表达式列表从左到右依次处理)将通过递归应用以下过程转换为位流,并追加到通用位流(即打包的位数组)的右端:
- 若表达式为流连接表达式或属于任何位流类型,
则应通过位流转换将其强制转换为打包的位数组(必要时包括将二态类型转换为四态类型),然后将该打包数组追加到通用位流的右端; - 若表达式为非紧凑数组(即队列、动态数组、关联数组或固定大小的非紧凑数组),
则此过程应依次应用于数组的每个元素。关联数组按索引排序顺序处理,其他非紧凑数组按仅使用单个索引变量的 foreach 循环遍历顺序处理; - 若表达式为结构体类型,
则此过程应依次应用于结构体的每个成员(按声明顺序); - 若表达式为无标签联合类型,
则此过程应应用于联合中第一个声明的成员。 - 若表达式为空类句柄,
该表达式应被跳过(不进行流式处理),并可发出警告; - 若表达式为非空类句柄,
此过程应依次应用于所引用对象的每个数据成员,而非句柄本身。类成员应按声明顺序进行流式处理。扩展类的成员应在其基类成员之后进行流式处理。包含循环的对象层次结构进行流式处理的结果将是未定义的,并可发出错误。若流式运算符所在位置无法访问本地或受保护成员,则流式处理包含此类成员的类句柄应视为非法; - 否则,
该表达式应被跳过(不进行流式处理),并应发出错误。
流的重排序
通过上一节所述操作得到的流,随后被分割为块并进行重排序。切片大小决定了每个块的比特数。
- 若未指定切片大小,则默认值为 1。
- 若指定切片大小,它可以是常量整型表达式或简单类型。
- 若使用类型,块大小应为该类型的比特数。
- 若使用常量整型表达式,其值为零或负值将报错。
流操作符 << 或 >> 决定了数据块的流动顺序:
>>使数据块按从左到右的顺序流动<<使数据块按从右到左的顺序流动使用
>>的左到右流动将忽略切片大小且不执行重排序。- 使用
<<的右到左流动将反转流中块的顺序,同时保留每个块内部的比特顺序。 - 对于使用
<<的右到左流动,流从最右比特开始按指定比特数分割为块。若分割后最后一个(最左)块的比特数少于块大小,则该块保留剩余比特数,不进行填充或截断。1
2
3
4
5
6
7
8int j = { "A", "B", "C", "D" };
{ >> {j} } // 生成流 "A" "B" "C" "D"
{ << byte {j} } // 生成流 "D" "C" "B" "A"(反转顺序)
{ << 16 {j} } // 生成流 "C" "D" "A" "B"
{ << { 8'b0011_0101 } } // 生成流 'b1010_1100(块大小=1,比特反转)
{ << 4 { 6'b11_0101 } } // 生成流 'b0101_11
{ >> 4 { 6'b11_0101 } } // 生成流 'b1101_01(相同)
{ << 2 { { << { 4'b1101 } } } } // 生成流 'b1110
作为赋值目标的流连接(解包)
当流连接作为赋值目标出现时,流运算符执行反向操作;即将比特流解包到一个或多个变量中。
- 源表达式必须为比特流类型,或是另一个流连接的结果
- 若源表达式包含的比特数超过所需数量,则应从其左端(最高有效位)开始消耗相应数量的比特
- 若所需比特数超过源表达式提供的数量,则会产生错误
- 将四态流解包到二态目标时需通过类型转换实现,反之亦然
- 空句柄在打包和解包操作中均会被跳过
- 解包操作不会创建类对象
- 若要从流中重建特定对象层次结构,必须在应用流运算符之前创建用于解包的对应对象层次结构
- 解包操作仅修改显式声明的属性,不会修改隐式声明的属性
1 | |
第十章 过程式编程语句
分支语句(if)
(Todo)
带违规检查的分支
关键字 unique、unique0 和 priority 可用于 if 语句之前以执行特定的违规检查。
若使用关键字 unique 或 priority,则当没有条件匹配且不存在显式 else 分支时,生成违规报告。例如:1
2
3
4
5
6
7unique if ((a==0) || (a==1)) $display("0 或 1");
else if (a == 2) $display("2");
else if (a == 4) $display("4"); // 值 3,5,6,7 会触发违规报告
priority if (a[2:1]==0) $display("0 或 1");
else if (a[2] == 0) $display("2 或 3");
else $display("4 到 7"); // 覆盖所有其他可能值,因此不会生成违规报告
若使用关键字 unique0,则当没有条件匹配时不会触发违规。例如:1
2
3unique0 if ((a==0) || (a==1)) $display("0 或 1");
else if (a == 2) $display("2");
else if (a == 4) $display("4"); // 值 3,5,6,7 不会触发违规报告
- unique-if 和 unique0-if 要求一系列 if-else-if 条件之间不存在重叠,即这些条件互斥,因此可以安全地并行求值。
- 在 unique-if 和 unique0-if 中,条件可以按任意顺序求值与比较。实现应在找到真条件后继续执行后续求值与比较。若发现多个条件为真,则违反 unique-if 或 unique0-if 规则。此时实现生成违规报告,并执行 if 语句中第一个出现的真条件对应的语句,但不会执行其他真条件对应的语句。
- 发现唯一性违规后,实现无需继续求值与比较其他条件。条件中的副作用可能导致非确定性结果。
- priority-if 表示一系列 if-else-if 条件应按所列顺序依次求值。在前述示例中,若变量 a 的值为 0,则其同时满足第一和第二个条件,此时需要优先级逻辑进行处理。
- unique、unique0 和 priority 关键字适用于整个 if-else-if 条件序列。在前述示例中,若在任意 else 出现后插入这些关键字均属非法操作。
- 若需在此类条件序列中嵌套另一个 if 语句,必须使用 begin-end 代码块进行封装。
| 语句 | 多个条件匹配 | 没有条件匹配 |
|---|---|---|
| if | 执行首个匹配 | 执行 else(如有) |
| priority if | 执行首个匹配 | 执行 else(如有),否则发出警告 |
| unique if | 执行首个匹配并发出警告 | 执行 else(如有),否则发出警告 |
| unique0 if | 执行首个匹配并发出警告 | 执行 else(如有),否则发出警告 |
选择语句(case)
case 语句是一种多路决策语句,它通过检测表达式是否与多个其他表达式中的某一个匹配,从而进行相应的分支处理。
- default 语句为可选项(default 后面的冒号也是可选的)
- 在一个 case 语句中使用多个 default 语句是不允许的
- case_expression 和 case_item_expression 不必是常量表达式
- case_expression 仅被计算一次,且计算时机早于所有 case_item_expressions
- case_item_expressions 将按它们出现的顺序依次计算并与 case_expression 进行比较
- 若存在默认 case_item,则在此线性搜索过程中将被忽略。在线性搜索期间,若某个 case_item_expression 与 case_expression 匹配,则执行该 case_item 对应的语句,并终止线性搜索。
- 若所有比较均失败且存在默认项,则执行默认项语句
- 若未提供默认语句且所有比较均失败,则不执行任何 case_item 语句
- 在 case_expression 比较中,仅当每个比特位相对于 0、1、x、z 值完全匹配时,比较才成功
- 所有 case_item_expressions 及 case_expression 的位宽均自动调整为最长 case_expression 和 case_item_expressions 的位宽
- 若任一表达式为无符号类型,则所有表达式均按无符号处理;若全部表达式均为有符号类型,则按有符号处理。
提供支持x和z值的case_expression比较机制,旨在检测此类值并降低其存在可能导致的悲观判断。
包含无关位的case语句
系统提供了另外两种 case 语句类型,用于在条件比较中处理无关位状态。
casez将高阻态值(z)视为无关位casex同时将高阻态(z)和未知值(x)视为无关位
在比较过程中,无论是 case_expression 还是 case_items 中的任何位出现无关值(casez 中的 z 值,casex 中的 z 和 x 值),该位都将被视为无关条件而不参与比较。字面数值的语法允许在这些 case 语句中使用问号(?)替代 z,这为在case语句中指定无关位提供了便捷的格式。
1 | |
使用常量表达式作为表达式
常量表达式可用于 case_expression。常量表达式的值将与 case_item_expressions 进行比较。1
2
3
4
5
6
7logic [2:0] encode ;
case (1)
encode[2] : $display("Select Line 2") ;
encode[1] : $display("Select Line 1") ;
encode[0] : $display("Select Line 0") ;
default $display("Error: One of the bits expected ON");
endcase
unique-case、unique0-case 与 priority-case
case、casez 和 casex 关键字可以通过 priority、unique 或 unique0 关键字进行限定,以执行特定的违规检查。
- priority-case 仅在第一个匹配项处执行 case_item 语句
- unique-case 和 unique0-case 断言不存在重叠的 case_item,因此可以安全地并行评估 case_item。
- 在 unique-case 和 unique0-case 中,case_item_expression 可以按任意顺序评估和比较。实现应在找到匹配的 case_item 后继续评估和比较。如果发现多个 case_item 与 case_expression 匹配,则违反 unique-case 和 unique0-case 规则,发出违规报告,并执行 case 语句中第一个匹配 case_item 关联的语句,但不执行其他匹配 case_item 关联的语句。
- 发现唯一性违规后,实现无需继续评估和比较其他 case_item
- 单个 case_item 包含多个匹配 case_expression 的 case_item_expression 不视为违反唯一性规则
- 如果某个 case_item_expression 匹配 case_expression,实现无需评估同一 case_item 中的其他 case_item_expression
- 如果 case 被限定为 priority 或 unique,且没有 case_item 匹配,仿真器发出违规报告。
- 如果 case 被限定为 unique0,则没有 case_item 匹配时,实现不发出违规报告。
- 通过指定 unique 或 priority,无需编写 default case 来捕获意外 case 值。
1 | |
| 语句 | 多个 case_item 匹配 | 没有 case_item 匹配 |
|---|---|---|
| case | 全部执行 | 执行 default(如有) |
| priority case | 执行首个匹配 | 执行 default(如有) |
| unique case | 执行首个匹配并发出警告 | 执行 default(如有),并发出警告 |
| unique0 case | 执行首个匹配并发出警告 | 执行 default(如有) |
集合成员 case 语句
(Todo)
循环语句(for)
for 循环
for 循环通过以下三步流程控制其关联语句的执行:
- 除非省略可选的 for_initialization 部分,否则执行一个或多个 for_initialization 赋值操作。这些赋值通常用于初始化控制循环次数的变量。
- 除非省略可选的 expression 部分,否则计算该 expression 的值。若结果为假,则退出for循环;否则(或当 expression 被省略时),for 循环将执行其关联语句并进入步骤3)。若表达式计算结果为未知值或高阻态,则按零值处理。
- 除非省略可选的 for_step 部分,否则执行一个或多个 for_step 赋值操作(通常用于修改循环控制变量的值),随后重复步骤2。
- 用于控制 for 循环的变量可在循环前声明。若两个或多个并行进程中的循环使用相同的循环控制变量,可能出现一个循环修改变量时其他循环仍在使用该变量的情况。
- 循环控制变量也可在循环内部声明,作为 for_initialization 赋值的一部分。这会在循环周围创建一个隐式的 begin-end 块,其中包含具有自动生命周期的循环变量声明。该块会形成新的层级作用域,使变量仅作用于循环局部范围。此块默认未命名,但可通过为 for 循环语句添加语句标签进行命名。因此,其他并行循环不会意外影响该循环的控制变量。
- 初始化声明或赋值语句可以是一个或多个由逗号分隔的语句
- 步进赋值同样可以是一个或多个由逗号分隔的赋值语句、递增或递减表达式,或函数调用。在 for 循环的初始化部分,控制变量要么全部局部声明,要么全部不局部声明。在上面的第二个循环示例中,count、done 和 j 都是局部声明的。而以下写法是非法的,因为它试图局部声明 y,而 x 却没有局部声明:
1
2
3
4for ( int count = 0; count < 3; count++ )
value = value + ((a[count]) * (count+1));
for ( int count = 0, done = 0, j = 0; j * count < 125; j++, count++)
$display("Value j = %d\n", j );在声明多个局部变量的 for 循环初始化中,局部变量的初始化表达式可以使用之前声明的局部变量。1
for (x = 0, int y = 0; ...)1
for (int i = 0, j = i+offset; i < N; i++,j++)
repeat 循环
repeat 循环会固定次数地执行一条语句。如果表达式的求值结果为未知 x 或高阻态 z,则将其视为零,且不会执行任何语句。
在以下 repeat 循环的示例中,通过加法与移位操作实现了一个乘法器:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15parameter size = 8, longsize = 16;
logic [size:1] opa, opb;
logic [longsize:1] result;
begin : mult
logic [longsize:1] shift_opa, shift_opb;
shift_opa = opa;
shift_opb = opb;
result = 0;
repeat (size) begin
if (shift_opb[1])
result = result + shift_opa;
shift_opa = shift_opa << 1;
shift_opb = shift_opb >> 1;
end
end
foreach 循环
foreach 循环结构用于遍历数组中的元素。其参数为一个标识符,用于指定任意类型的数组,后跟一个由方括号括起、以逗号分隔的循环变量列表。每个循环变量对应数组的一个维度。foreach 循环类似于 repeat 循环,区别在于它使用数组的边界来指定迭代次数,而不是通过表达式。1
2
3
4
5
6string words [2] = '{ "hello", "world" };
int prod [1:8] [1:3];
foreach( words [ j ] )
$display( j , words[j] ); // print each index and value
foreach( prod[ k, m ] )
prod[k][m] = k * m; // initialize
- 循环变量的数量不应超过数组变量的维度数
- 可以省略循环变量以表示不迭代数组的该维度,列表中的尾随逗号也可省略
- 与 for 循环类似,foreach 循环会在循环语句周围创建一个隐式的 begin-end 块,其中包含具有自动生命周期的循环变量声明。该块创建了一个新的层次作用域,使变量成为循环作用域的局部变量。默认情况下该块未命名,但可通过在 foreach 语句中添加语句标签来命名。
- foreach 循环变量是只读的
- 每个循环变量的类型被隐式声明为与数组索引类型一致
- 任何循环变量与数组同名均属错误
- 循环变量与数组索引的映射关系由维度基数决定,foreach 循环会使较高基数的索引变化更快
- 若在迭代 foreach 循环结构时动态调整数组维度,结果将未定义并可能导致生成无效索引值。
- 当循环变量在非指定数组索引的表达式中使用时,会自动转换为与索引类型一致的类型。对于固定大小数组和动态数组,自动转换类型为 int。对于通过特定索引类型建立索引的关联数组,自动转换类型与索引类型相同。如需使用其他类型,可采用显式类型转换。第一个 foreach 循环使 i 从 0 迭代到 1,j 从 0 迭代到 2,k 从 0 迭代到 3。第二个 foreach 循环使 q 从 5 迭代到 1,r 从 0 迭代到 3,s 从 2 迭代到 1(跳过了第三索引的迭代)。
1
2
3
4
5// 维度编号示例
int A [2][3][4]; // 维度编号:1 2 3
bit [3:0][2:1] B [5:1][4]; // 维度编号:3 4 1 2
foreach( A [ i, j, k ] ) ... // 遍历三维数组
foreach( B [ q, r, , s ] ) ... // 跳过第三维遍历
while循环
只要控制表达式为真,while 循环就会重复执行语句。如果在 while 循环开始执行时表达式不为真,则语句根本不会被执行。
以下示例统计数据中逻辑1值的数量:1
2
3
4
5
6
7
8
9
10begin : count1s
logic [7:0] tempreg;
count = 0;
tempreg = data;
while (tempreg) begin
if (tempreg[0])
count++;
tempreg >>= 1;
end
end
do…while循环
do…while 循环与 while 循环的区别在于,do…while 循环在循环结束时测试其控制表达式。在末尾进行测试的循环有时有助于避免循环体的重复。1
2
3
4
5string s;
if ( map.first( s ) )
do
$display( "%s : %d\n", s, map[ s ] );
while ( map.next( s ) );
条件可以是任何可视为布尔值的表达式。它在语句执行后求值。
forever循环
forever 循环会重复执行语句。为避免可能导致仿真事件调度器挂起的零延迟无限循环,forever 循环应仅与定时控制或 disable 语句结合使用。例如:1
2
3
4
5
6
7
8initial begin
clock1 <= 0;
clock2 <= 0;
fork
forever #10 clock1 = ~clock1;
#5 forever #10 clock2 = ~clock2;
join
end
跳转语句(jump)
(Todo)
第十一章 任务与函数(子程序)
任务与函数提供了在描述中从多个不同位置执行通用程序的能力。它们还提供了一种将大型程序拆分为较小程序的方法,以便更易于阅读和调试源代码。任务与函数统称为子程序。
以下规则区分任务与函数:
- 函数体中的语句应在单个仿真时间单位内执行;任务可包含时间控制语句。
- 函数不能调用任务;任务可调用其他任务和函数。
- 非空函数应返回单个值;任务或空函数不应返回值。
- 非空函数可用作表达式中的操作数;该操作数的值为函数返回的值。
任务
任务应从定义传递参数值及接收结果变量的语句中调用。任务完成后,控制权应返回给调用进程。因此,若任务内部包含时序控制,则调用任务的时间可能与控制权返回的时间不同。任务可调用其他任务,被调用的任务又可继续调用其他任务——调用任务的数量没有限制。无论调用了多少任务,在所有调用任务完成前,控制权不应返回。(注意不是线程完成,任务允许通过 fork 等方式开启后台线程)
任务声明的形式参数可以放在括号内(类似于ANSI C),也可以放在声明和指示中。1
2
3
4
5
6
7
8
9
10
11task mytask1 (output int x, input logic y);
...
endtask
task mytask2;
output x;
input y;
int x;
logic y;
...
endtask
任务定义与调用
每个形式参数具有以下方向之一:
input:在开始时复制值输入output:在结束时复制值输出inout:在开始时复制输入并在结束时复制输出ref:传递引用
如果未指定方向,则默认方向为输入。一旦指定了方向,后续的形式参数默认采用相同的方向。在以下示例中,形式参数 a 和 b 默认为输入,而 u 和 v 均为输出:1
2
3task mytask3(a, b, output logic [15:0] u, v);
...
endtask
每个形式参数都有一个数据类型,可以显式声明或从前一个参数继承。如果未显式声明数据类型,则默认数据类型为 logic(如果它是第一个参数或参数方向已显式指定)。否则,数据类型从前一个参数继承。数组可以指定为任务的形式参数。例如:1
2
3
4// b的最终声明为 input [3:0][7:0] b[3:0]
task mytask4(input [3:0][7:0] a, b[3:0], output [3:0][7:0] y[1:0]);
...
endtask
在任务声明和结束任务之间可以编写多个语句。这些语句按顺序执行,就像它们被包含在一个 begin…end 组中一样。完全不包含任何语句也是合法的。
当遇到结束任务时,任务退出。可以使用return语句在结束任务关键字之前退出任务。
示例:以下示例展示了一个包含五个参数的任务定义的基本结构:1
2
3
4
5
6
7
8
9task my_task;
input a, b;
inout c;
output d, e;
...
c = a;
d = b;
e = c;
endtask
以下语句调用了任务:initial my_task(v, w, x, y, z);
任务调用参数(v、w、x、y 和 z)对应于任务定义的参数(a、b、c、d 和 e)。在调用时,输入类型和输入输出类型参数(a、b 和 c)接收从 v、w 和 x 传递来的值。因此,执行调用实际上会触发以下赋值操作:1
2
3a = v;
b = w;
c = x;
作为任务处理的一部分,my_task 的任务定义将计算结果值存入 c、d 和 e 中。当任务完成时,会执行以下赋值操作,将计算值返回给调用进程:1
2
3x = c;
y = d;
z = e;
静态任务与自动任务
在模块、接口、程序或包中定义的任务默认为静态任务,其所有声明项均为静态分配。这些项将在所有并发执行的任务实例间共享。可通过以下两种方式将任务定义为使用自动存储:
- 在任务声明中显式使用可选的 automatic 关键字;
通过将任务定义在已声明为 automatic 的模块、接口、程序或包中隐式声明。
在类中定义的任务始终为自动任务
- 自动任务内部声明的所有项在每次调用时动态分配,所有形式参数和局部变量均存储在堆栈中。
- 自动任务中的项不可通过层次化引用访问,但可通过层次化名称调用自动任务。
- 静态任务中可声明特定局部变量为自动类型,自动任务中也可声明特定局部变量为静态类型。
任务内存使用与并发调用
任务可能被多次并发调用。自动任务的所有变量在每次并发调用时复制,以存储该次调用特有的状态。静态任务的所有变量均为静态变量,即模块实例中每个声明的局部变量仅对应单一变量,不受任务并发调用次数影响。但不同模块实例中的静态任务应拥有相互独立的存储空间。
- 静态任务中声明的变量(包括 input、output 和 inout 类型参数)在仿真开始时初始化为默认值,并在多次调用间保留其值。
- 自动任务中声明的变量(包括 output 类型参数)在每次执行进入其作用域时初始化为默认值,input 和 inout 类型参数则初始化为任务调用语句中对应参数表达式的传递值。
由于自动任务中声明的变量在任务调用结束时释放,它们不得用于可能在释放后仍引用这些变量的场景:
- 不可通过非阻塞赋值或过程连续赋值为其赋值
- 不可被过程连续赋值或过程强制语句引用
- 不可在非阻塞赋值的赋值内事件控制中引用
- 不可被 $monitor、$dumpvars 等系统任务追踪
函数
函数的主要目的是返回一个用于表达式的值。无返回值函数(void function)也可用于替代任务(task),以定义在单个时间步内执行并返回的子程序。
函数具有确保其在执行过程中不会挂起进程的限制。
- 函数不得包含任何时间控制语句,即任何包含
#、##、@、fork-join、fork-join_any、wait、wait_order或expect的语句。 - 函数不得调用任务,无论这些任务是否包含时间控制语句。
- 函数可以调用细粒度进程控制方法来挂起自身或其他进程。
为了指明函数的返回类型,其声明可以包含显式的数据类型或 void,或者使用仅指示紧凑维度范围(可选择性地包括有符号性)的隐式语法。当使用隐式语法时,返回类型等同于在该隐式语法前紧接 logic 关键字的情况。特别地,隐式语法可以为空,此时返回类型为 logic 标量。函数也可以为 void 类型,即没有返回值。
函数声明中的形式参数可以采用括号形式(类似 ANSI C)或通过声明和方向指示符来定义,如下所示:1
2
3
4
5
6
7
8
9function logic [15:0] myfunc1(int x, int y);
...
endfunction
function logic [15:0] myfunc2;
input int x;
input int y;
...
endfunction
函数的形式参数可以与任务具有相同的类型。函数参数的方向如下:
input// 起始时传入值output// 结束时传出值inout// 起始传入且结束时传出ref// 传递引用
若未指定方向,函数声明默认将形式参数方向设为 input。一旦指定某个参数的方向,后续参数默认沿用相同方向。
每个形式参数都具有数据类型,可以显式声明或从前一个参数继承。若未显式声明数据类型,则当该参数是首个参数或已显式指定参数方向时,默认数据类型为 logic;否则将从前一个参数继承数据类型。数组可作为函数的形式参数。
在事件表达式、过程连续赋值内的表达式或非过程语句内的表达式中,调用带有 output、inout 或 ref 参数的函数是非法的。但在此类上下文中,const ref函数参数是合法的。
函数头部与 endfunction 之间可以编写多条语句。这些语句按顺序执行,如同被包含在 begin-end 块中。完全不包含语句也是合法的,此时函数将返回与函数同名的隐式变量的当前值。
返回值与空函数
函数定义应隐式声明一个函数内部的变量,该变量与函数同名,且类型与函数返回值相同。函数返回值可通过两种方式指定:一是使用return语句,二是为与函数同名的内部变量赋值。例如:1
2
3
4
5
6
7function [15:0] myfunc1 (input [7:0] x,y);
myfunc1 = x * y - 1; // 将返回值赋给函数名
endfunction
function [15:0] myfunc2 (input [7:0] x,y);
return x * y - 1; // 使用return语句指定返回值
endfunction
- return 语句将覆盖已赋给函数名的任何值。
- 使用 return 语句时,非空函数必须通过 return 指定一个表达式。
- 函数返回值可以是结构体或联合体。在这种情况下,函数内部以函数名开头的层次化名称将被解释为返回值的成员。若在函数外部使用函数名,该名称表示整个函数的作用域;若在层次化名称中使用函数名,同样表示整个函数的作用域。
- 函数可声明为空类型(void),此类函数无返回值。除非是空类型函数,否则函数调用可用作表达式;空类型函数调用则作为语句:有返回值的函数可用于赋值或表达式中。将非空函数当作无返回值调用是合法的,但会产生警告。若需将函数用作语句且丢弃返回值而不产生警告,可将函数调用强制转换为空类型:
1
2
3
4
5
6a = b + myfunc1(c, d); // 将myfunc1(上文定义)作为表达式调用
myprint(a); // 将myprint(下文定义)作为语句调用
function void myprint (int a);
...
endfunction在函数声明或显式导入的作用域内,声明与函数同名的其他对象是非法的。在函数作用域内部声明与函数同名的其他对象同样非法。1
void'(some_function());
静态与自动函数
在模块、接口、程序或包中定义的函数默认为静态函数,其所有声明的项均为静态分配。这些项将在并发执行的所有函数调用中共享。可通过以下两种方式将函数定义为使用自动存储:
- 在函数声明中通过可选的
automatic关键字显式声明; 在定义为
automatic的模块、接口、程序或包内隐式声明该函数。在类中定义的函数总是自动的
- 自动函数是可重入的,所有函数声明会为每个并发函数调用动态分配存储空间
- 无法通过层次化引用访问自动函数项,但可以通过其层次化名称调用自动函数
- 在静态函数中可将特定局部变量声明为自动变量,在自动函数中也可将特定局部变量声明为静态变量
常量函数
常量函数是普通函数的一个子集,必须满足以下约束条件:
- 常量函数不得包含输出(output)、输入输出(inout)或引用(ref)参数
- 返回类型不能为 void
- 不能有 DPI 导入函数
- 不得包含在函数返回后直接调度事件执行的语句
- 不得包含任何 fork 结构
- 不得包含任何层次化引用
- 在常量函数内部调用的任何函数必须是当前模块内部的常量函数
- 允许调用所有在常量表达式中允许的系统函数,包括
$bits和数组查询函数。调用其他系统函数是非法的 - 常量函数内部的所有系统任务调用应被忽略
- 函数内部使用的所有参数值必须在调用常量函数之前定义(即,在计算常量函数调用时使用的任何参数,都视为在原常量函数调用位置使用了该参数)。常量函数可以引用包或
$unit中定义的参数。 - 所有非参数或非函数的标识符必须在当前函数内部局部声明
- 如果常量函数使用的参数值直接或间接受
defparam语句影响,结果将是未定义的。这可能导致错误,或使常量函数返回不确定的值。 - 常量函数不应在生成块内部声明
- 常量函数本身不应在需要常量表达式的上下文中使用其他常量函数
- 常量函数可以有默认参数值,但任何此类默认参数值必须是常量表达式
常量函数调用用于支持在编译阶段进行复杂数值计算。常量函数调用是指调用当前模块内部、包中或 $unit 中的常量函数,且函数的所有参数均为常量表达式。
常量函数调用在编译阶段进行计算。其执行对仿真时使用的变量初始值,或在编译阶段多次调用函数时的变量值均无影响。在上述所有情况下,变量的初始化方式与正常仿真时相同。
函数内发起的后台线程
函数应无延迟执行。因此,调用函数的进程应立即返回。但是,函数内部允许使用非阻塞语句;具体而言,函数内部允许使用非阻塞赋值、事件触发、时钟驱动以及 fork-join_none 结构。若函数尝试调度一个在其返回后才能激活的事件,只要调用该函数的线程由初始过程、always 过程或这些过程中的 fork 块创建,且处于允许副作用的环境中,则此类调用是允许的。若未满足这些条件,则在编译时或运行时报错。在函数内部,fork-join_none 结构可包含任务中合法的任何语句。以下示例展示了函数中 fork-join_none 的合法与非法用法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26class IntClass;
int a;
endclass
IntClass address = new(), stack = new();
function automatic bit watch_for_zero( IntClass p );
fork
forever @p.a begin
if ( p.a == 0 ) $display("Unexpected zero");
end
join_none
return ( p.a == 0 );
endfunction
function bit start_check();
return ( watch_for_zero( address ) | watch_for_zero( stack ) );
endfunction
bit y = watch_for_zero( stack ); // 非法
initial if ( start_check() ) $display( "OK" ); // 合法
initial fork
if ( start_check() ) $display( "OK too" ); // 非法
join_none
参数定义与传参方法
- 如果子程序中的参数被声明为输入,则子程序调用中对应的表达式可以是任何表达式。参数列表中表达式的求值顺序是未定义的。
- 如果子程序中的参数被声明为输出或输入输出,则子程序调用中对应的表达式应仅限于过程赋值左侧有效的表达式。
- 子程序调用的执行应将输入值从调用参数列表中的表达式传递进来。
- 子程序返回的执行应将输出和输入输出类型参数的值传递回子程序调用中对应的变量。
- SystemVerilog提 供了两种向任务和函数传递参数的方式:按值传递和按引用传递。
- 参数也可以通过名称绑定以及位置绑定。
- 子程序参数还可以设置默认值,允许调用子程序时不传递参数。
按值传递
按值传递是向子程序传递参数的默认机制。这种参数传递机制通过将每个参数复制到子程序区域来实现。如果子程序是自动的,则子程序在其栈中保留参数的本地副本。如果在子程序内修改了参数,这些修改在子程序外部不可见。当参数较大时,复制参数可能并不理想。此外,程序有时需要共享未声明为全局的公共数据。
例如,调用以下函数时,每次调用都会复制1000字节:1
2
3
4
5function automatic int crc( byte packet [1000:1] );
for( int j= 1; j <= 1000; j++ ) begin
crc ^= packet[j];
end
endfunction
按引用传递
通过引用传递的参数不会被复制到子程序区域,而是将原始参数的引用传递给子程序。子程序随后可以通过该引用访问参数数据。通过引用传递的参数必须与等效的数据类型匹配。不允许进行类型转换。为了表示通过引用传递参数,参数声明前需添加 ref 关键字。对于生命周期为静态的子程序,使用引用传递参数是非法的。
例如,前面的示例可以改写为:1
2
3
4
5function automatic int crc( ref byte packet [1000:1] );
for( int j= 1; j <= 1000; j++ ) begin
crc ^= packet[j];
end
endfunction
如上述示例所示,除了添加 ref 关键字外无需其他更改。编译器知道 packet 现在通过引用寻址,但用户无需在被调用方或调用点显式处理这些引用。换句话说,调用任一版本的 crc 函数的方式保持不变:1
2byte packet1[1000:1];
int k = crc( packet1 ); // 按值传递或按引用传递:调用方式相同
当参数通过引用传递时,调用方和子程序共享参数的同一表示形式;因此,在调用方或子程序中对参数所做的任何更改对双方均可见。对通过引用传递的变量进行赋值的语义是:更改在子程序外部立即可见(在子程序返回之前)。
- 通过引用传递参数是一种独特的参数传递限定符,与
input、output或inout不同。将ref与其他方向限定符组合使用是非法的。 ref参数与inout参数类似,不同之处在于inout参数会被复制两次:一次是在调用子程序时从实参复制到形参,另一次是在子程序返回时从形参复制回实参。- 传递对象句柄也不例外,当作为
ref或inout参数传递时具有相似的语义 - 对象句柄的
ref允许修改对象句柄(例如,分配新对象),同时也可以修改对象的内容 - 为了防止通过引用传递的参数被子程序修改,可以使用
const限定符与ref结合,表示该参数虽然是按引用传递的,但它是只读变量。 - 当形参被声明为
const ref时,子程序不能修改变量,尝试这样做会导致编译器错误。1
2
3
4task automatic show ( const ref byte data [] );
for ( int j = 0; j < data.size ; j++ )
$display( data[j] ); // data 可读但不可写
endtask
仅以下类型允许通过引用传递:
- 变量
- 类属性
- 非压缩结构的成员
非压缩数组的元素
线网及对线网的选择不得通过引用传递
- 由于通过引用传递的变量可能是自动变量,
ref参数不得用于自动变量被禁止的任何上下文中 - 通过引用传递的动态数组、队列和关联数组的元素可能在被子程序调用完成前被移除,或数组可能被调整大小
- 通过引用传递的特定数组元素在被子程序的作用域内将继续存在,直到这些子程序执行完毕
- 如果数组元素在更改前已从数组中移除,则被子程序对数组元素值的更改在这些子程序作用域外不可见。这些引用称为过时引用。
对可变大小数组的以下操作将导致对该数组元素的现有引用变为过时引用:
- 通过隐式或显式
new[]调整动态数组大小 - 通过
delete()方法删除动态数组 - 关联数组中引用的元素通过
delete()方法被删除 - 包含引用元素的队列或动态数组通过赋值进行更新
- 队列中被引用的元素通过队列方法被删除
默认参数值
为了处理常见情况或允许未使用的参数,SystemVerilog 允许在子程序声明中为每个单一参数指定默认值。在子程序中声明默认参数的语法如下:1
subroutine( [ direction ] [ type ] argument = default_expression );
- 可选的方向可以是
input、inout、output或ref - 每次调用使用默认值时,default_expression 会在包含子程序声明的范围内进行计算
- 如果未使用默认值,则不会计算默认表达式
- 默认值仅允许在 ANSI 风格声明中使用
- 当调用子程序时,可以省略具有默认值的参数,编译器会插入相应的值
- 未指定(或空)参数可以用作默认参数的占位符
- 如果对没有默认值的参数使用未指定参数,编译器会报错此示例声明了一个具有两个默认参数
1
2
3task read(int j = 0, int k, int data = 1 );
...
endtaskj和data的任务read()。然后可以使用各种默认参数调用该任务:以下示例展示了一个带有默认表达式的输出参数:1
2
3
4
5
6
7read( , 5 ); // 等价于 read( 0, 5, 1 );
read( 2, 5 ); // 等价于 read( 2, 5, 1 );
read( , 5, ); // 等价于 read( 0, 5, 1 );
read( , 5, 7 ); // 等价于 read( 0, 5, 7 );
read( 1, 5, 2 ); // 等价于 read( 1, 5, 2 );
read( ); // 错误:k 没有默认值
read( 1, , 7 ); // 错误:k 没有默认值1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27module m;
logic a, w;
task t1 (output o = a) ; // 默认绑定到 m.a
...
endtask :t1
task t2 (output o = b) ; // 非法,b 无法解析
...
endtask :t2
task t3 (inout io = w) ; // 默认绑定到 m.w
...
endtask :t3
endmodule :m
module n;
logic a;
initial begin
m.t1();
// 等同于 m.t1(m.a),而非 m.t1(n.a);
// 任务结束时,t1.o 的值被复制到 m.a
m.t3(); // 等同于 m.t3(m.w)
// 任务开始时 m.w 的值被复制到 t3.io,
// 任务结束时 t3.io 的值被复制到 m.w
end
endmodule :n
按名称绑定参数
SystemVerilog 允许任务和函数的参数通过名称或位置进行绑定。这使得可以指定非连续的默认参数,并便于在调用时明确传递的参数。例如:1
2
3function int fun( int j = 1, string s = "no" );
...
endfunction
函数 fun 可按以下方式调用:1
2
3
4
5
6
7
8fun( .j(2), .s("yes") ); // fun( 2, "yes" );
fun( .s("yes") ); // fun( 1, "yes" );
fun( , "yes" ); // fun( 1, "yes" );
fun( .j(2) ); // fun( 2, "no" );
fun( .s("yes"), .j(2) ); // fun( 2, "yes" );
fun( .s(), .j() ); // fun( 1, "no" );
fun( 2 ); // fun( 2, "no" );
fun( ); // fun( 1, "no" );
- 如果参数具有默认值,它们将被视为模块实例的参数
- 如果参数没有默认值,则必须提供这些参数,否则编译器将报错
- 如果在单个子程序调用中同时指定了位置参数和命名参数,则所有位置参数必须位于命名参数之前
1
2fun( .s("yes"), 2 ); // 非法
fun( 2, .s("yes") ); // 合法
可选参数列表
当无返回值函数或类函数方法未指定参数时,子程序名后的空括号 () 是可选的。对于需要参数的任务、无返回值函数和类方法,若所有参数均已指定默认值,此规则同样适用。在非层级限定的直接递归非空类函数方法调用中省略括号是非法的。
任务/函数名
(Todo)
参数化的任务/函数
(Todo)
第十二章 时钟块(Clocking block)
- 时钟块结构用于标识时钟信号,并捕获所建模模块的时序与同步要求。
- 时钟块将同步于特定时钟的信号整合在一起,并显式定义其时序关系。
- 对时钟块信号的采样和驱动时序是隐式的,且相对于时钟块的时钟进行。这使得一系列关键操作能够以极其简洁的方式编写,无需显式调用时钟或指定时序。这些操作包括:
- 同步事件
- 输入采样
- 同步驱动
delay_control应为时间字面量或计算结果为正整数值的常量表达式。clocking_identifier指定所声明的时钟块名称。仅默认时钟块允许未命名,未命名时钟块中的声明不可被引用。signal_identifier指定时钟块声明所在作用域内的信号(线网或变量),并在时钟块中定义一个时钟变量(称为时钟信号)- 除非使用层次化表达式,否则时钟信号与时钟变量名称必须相同
- 若时钟信号指向受限于过程块的变量,则属非法
clocking_event指定作为时钟块时钟的特定事件。驱动和采样给定时钟块中所有其他信号所采用的时序由其时钟事件控制。- 对
clocking_direction为input的时钟变量进行写入操作属非法。 - 读取
clocking_direction为output的时钟变量的值属非法。 clocking_direction为inout的时钟变量应表现为两个同名且对应同一时钟信号的时钟变量(一个input类型,一个output类型)。读取此类inout时钟变量的值等同于读取对应的input时钟变量,写入此类inout时钟变量等同于写入对应的output时钟变量。clocking_skew决定了信号在距离时钟事件多少个时间单位处被采样或驱动- 输入偏移默认为负值,即始终指向时钟事件之前的时间;而输出偏移则始终指向时钟事件之后的时间
- 当时钟事件指定为简单边沿而非具体数值时,偏移可被指定为信号的特定边沿
- 通过默认时钟项(default clocking item)可为整个时钟块设置统一的偏移值
- 默认输入偏移为
1step,默认输出偏移为0
1 | |
分配给时钟变量的表达式指定了与时钟块关联的信号需关联到特定的层次化表达式。例如,可使用跨模块引用替代本地端口。1
2
3
4
5
6clocking bus @(posedge clock1); // 声明了名为 bus 的时钟块,其时钟事件为信号 clock1 的上升沿
default input #10ns output #2ns; // 指定该时钟块内所有信号默认采用 10ns 输入偏移和 2ns 输出偏移
input data, ready, enable = top.mem1.enable; // 向时钟块添加三个输入信号:data、ready 和 enable;其中最后一个信号指向层次化信号 top.mem1.enable
output negedge ack; // 将信号 ack 加入时钟块,并覆盖默认输出偏移,使 ack 在时钟下降沿被驱动
input #1step addr; // 添加信号addr,并覆盖默认输入偏移,使addr在时钟上升沿的前一步(1step)被采样
endclocking
注意:语法元素 clocking_skew 包含 edge_identifier 加可选的 delay_control 或者单独 delay_control,故 output negedge ack 会覆盖 default,其相当于 output negedge #0 ack。
输入/输出偏移
- 输入 input(或 inout)信号在指定的时钟事件处进行采样。若指定了输入偏移时间,则信号会在时钟事件前偏移时间单位处被采样。
- 输出 output(或 inout)信号会在对应时钟事件后偏移仿真时间单位处被驱动。
- 偏移量应为一个常量表达式,并可指定为参数
- 若偏移量未明确时间单位,则采用当前时间单位
- 若使用纯数字表示,偏移量将依据当前作用域的时间尺度进行解析
1 | |
- 输入偏移为
1step表示信号将在上一个时间步结束时被采样。换言之,采样的值始终是对应时钟边沿之前信号的最后一个值。 - 当程序块外部的事件控制对与时钟块相同的时钟敏感,且事件控制后的语句试图读取时钟块成员时,时钟块并不能消除潜在的竞争风险。这种竞争存在于读取旧采样值和新采样值之间。
- 具有显式
#0偏移的输入信号将在与其对应时钟事件相同的时间被采样,但为避免竞争,采样操作将在观察区(Observed region)进行。 - 无偏移(或显式
#0偏移)的时钟块输出信号将在重新非阻塞赋值区(Re-NBA region)中,与其指定时钟事件同时被驱动。 - 偏移是声明性结构,因此其语义与语法相似的过程延迟语句有本质区别
- 显式
#0偏移不会暂停任何进程,也不会在非活跃区(Inactive region)执行操作或采样数值
时钟块在接口中的方向问题
由于测试平台内时钟块中的信号方向是相对于测试平台而非被测设计的,因此 modport 声明可以恰当地描述任一方向。从测试平台侧(即 modport test)看,接口中的连线方向与时钟块中指定的方向相同;而从被测设计侧(即 modport dut)看,方向则相反。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31interface bus_A (input clk);
logic [15:0] data;
logic write;
modport test (input data, output write);
modport dut (output data, input write);
endinterface
interface bus_B (input clk);
logic [8:1] cmd;
logic enable;
modport test (input enable);
modport dut (output enable);
endinterface
program test( bus_A.test a, bus_B.test b );
clocking cd1 @(posedge a.clk);
input data = a.data;
output write = a.write;
inout state = top.cpu1.state;
endclocking
clocking cd2 @(posedge b.clk);
input #2 output #4ps cmd = b.cmd;
input en = b.enable;
endclocking
initial begin
...
// 此处可以访问 cd1.data, cd1.write, cd1.state, cd2.cmd, and cd2.en
end
endprogram
时钟块事件访问
时钟块的时钟事件可以直接通过使用时钟块名称来访问,而无需考虑实际用于声明时钟块的时钟事件。例如:1
2
3
4clocking dram @(posedge phi1);
inout data;
output negedge #1 address;
endclocking
dram时钟块的时钟事件可用于等待该特定事件:1
@(dram);
上述语句等同于 @(posedge phi1)。
第十三章 进程间同步与通信
概述
高级且易于使用的同步与通信机制对于控制复杂系统或高响应性测试平台中动态进程间的交互至关重要。
基本的同步机制是命名事件类型,以及事件触发和事件控制结构(即 -> 和 @)。这种控制方式仅限于静态对象,适用于硬件级和简单系统级的同步,但无法满足高度动态、高响应性测试平台的需求。
SystemVerilog 还提供了一套强大且易于使用的同步与通信机制,这些机制可以动态创建和回收。该机制包括一个用于共享资源同步与互斥的内置信号量类(Semaphore),以及一个用于进程间通信通道的内置邮箱类(Mailbox)。
信号量和邮箱是内置类型,但它们本质上是类,可以作为基类派生出更高级的类。这些内置类位于内置的 std 包中,因此用户代码可以在任何其他作用域中重新定义它们。
信号量(Semaphores)
从概念上讲,信号量是一个桶。当分配一个信号量时,会创建一个包含固定数量钥匙的桶。使用信号量的进程必须先从桶中获取钥匙,才能继续执行。如果某个特定进程需要钥匙,则同时只能有固定数量的该进程实例运行,其他进程必须等待足够数量的钥匙被归还到桶中。信号量通常用于互斥、共享资源的访问控制和基本同步。
1 | |
信号量是一个内置类,提供以下方法:
- 创建具有指定数量钥匙的信号量:
new() - 从桶中获取一个或多个钥匙:
get() - 将一个或多个钥匙归还到桶中:
put() - 尝试获取一个或多个钥匙而不阻塞:
try_get()
内置成员函数
new()用于创建信号量:参数 keyCount 指定初始分配给信号量桶的钥匙数量。当放入信号量的钥匙数量多于取出数量时,桶中的钥匙数量可以超过 keyCount。keyCount 的默认值为 0。1
function new(int keyCount = 0);new()函数返回信号量的句柄。put()用于向信号量归还钥匙:参数 keyCount 指定要归还给信号量的钥匙数量,默认值为 1。当调用1
function void put(int keyCount = 1);semaphore.put()函数时,指定数量的钥匙将被归还给信号量。如果有进程因等待钥匙而挂起,且归还的钥匙数量足够,则该进程将恢复执行。get()方法用于从信号量获取指定数量的钥匙参数 keyCount 指定要从信号量获取的钥匙数量,默认值为 1。如果指定数量的钥匙可用,该方法将返回并继续执行;如果钥匙数量不足,进程将阻塞直到钥匙可用。信号量的等待队列遵循先进先出(FIFO)原则,这并不保证进程到达队列的顺序,但确保信号量会维持它们的到达顺序。1
task get(int keyCount = 1);try_get()方法用于从信号量获取指定数量的钥匙,但不会阻塞进程:参数 keyCount 指定要从信号量获取的钥匙数量,默认值为 1。如果指定数量的键可用,该方法将返回一个正整数并继续执行。如果指定数量的键不可用,该方法将返回0。1
function int try_get(int keyCount = 1);
邮箱(Mailbox)
邮箱是一种通信机制,允许进程之间交换消息。一个进程可以将数据发送到邮箱,而另一个进程可以从中检索数据。从概念上讲,邮箱的行为类似于真实的邮箱。当一封信被投递并放入邮箱时,收件人可以取出信件(以及其中存储的任何数据)。然而,如果在检查邮箱时信件尚未送达,收件人必须选择是等待信件还是下次访问邮箱时再取信。类似地,SystemVerilog 的邮箱提供了一种受控的方式,使进程能够传输和检索数据。邮箱在创建时具有有界或无界的队列大小。当有界邮箱包含指定数量的消息时,邮箱将变为满状态。尝试将消息放入已满邮箱的进程将被挂起,直到邮箱队列中有足够的空间。无界邮箱在发送操作中永远不会挂起线程。1
mailbox mbxRcv;
邮箱是一个内置类,提供以下方法:
- 创建邮箱:
new() - 将消息放入邮箱:
put() - 尝试将消息放入邮箱而不阻塞:
try_put() - 从邮箱检索消息:
get()或peek() - 尝试从邮箱检索消息而不阻塞:
try_get()或try_peek() - 获取邮箱中的消息数量:
num()
内置成员函数
new()方法创建新的邮箱1
function new(int bound = 0);new()函数返回邮箱句柄。如果 bound 参数为 0,则邮箱为无界(默认情况),put()操作永远不会阻塞。如果 bound 非零,则它表示邮箱队列的大小。bound 必须为正数。负的边界值是无效的,可能导致不确定的行为,但可能发出警告。num()方法获取邮箱中的消息数量1
function int num();num()方法返回当前邮箱中的消息数量。使用返回值时需谨慎,因为该数值仅在下次对邮箱执行get()或put()操作前有效。这些邮箱操作可能来自与执行num()方法不同的进程。因此,返回值的有效性取决于其他方法的开始与结束时间。put()方法用于将消息放入邮箱消息可以是任何单一表达式,包括对象句柄。1
task put( singular message );put()方法严格按照先进先出(FIFO)的顺序将消息存入邮箱。如果邮箱创建时设置了有界队列,当队列空间不足时,当前进程将被挂起,直到队列中有足够空间。try_put()方法尝试将消息放入邮箱消息可以是任何单一表达式,包括对象句柄。1
function int try_put( singular message );try_put()方法严格按照先进先出(FIFO)顺序将消息存入邮箱。此方法仅对有界邮箱有意义。如果邮箱未满,则指定的消息会被存入邮箱,并返回一个正整数;如果邮箱已满,则返回 0。get()方法从邮箱中获取消息1
task get( ref singular message );try_get()方法尝试从邮箱中获取消息而不阻塞消息可以是任何单数表达式,且必须是有效的左值表达式。1
function int try_get( ref singular message );try_get()方法尝试从邮箱中获取一条消息。如果邮箱为空,则方法返回 0。如果消息变量的类型与邮箱中消息的类型不匹配,则方法返回负整数。如果消息可用且消息类型与消息变量的类型匹配,则消息被获取,方法返回正整数。peek()方法从邮箱中复制一条消息,但不会将消息从队列中移除消息可以是任何单数表达式,且必须是有效的左值表达式。1
task peek( ref singular message );peek()方法从邮箱中复制一条消息,但不会将消息从邮箱队列中移除。如果邮箱为空,则当前进程会阻塞,直到有消息被放入邮箱。如果消息变量的类型与邮箱中消息的类型不匹配,则会产生运行时错误。
调用peek()方法也可能导致一条消息解除多个进程的阻塞。只要消息保留在邮箱队列中,任何因peek()或get()操作而阻塞的进程都将被解除阻塞。try_peek()方法尝试从邮箱中复制消息而不阻塞消息可以是任何单数表达式,且必须是有效的左值表达式。1
function int try_peek( ref singular message );try_peek()方法尝试从邮箱中复制一条消息,但不会将消息从邮箱队列中移除。如果邮箱为空,则方法返回 0。如果消息变量的类型与邮箱中消息的类型不匹配,则方法返回负整数。如果消息可用且其类型与消息变量的类型匹配,则消息被复制,方法返回正整数。
参数化邮箱
非参数化邮箱是无类型的,即单个邮箱可以发送和接收不同类型的数据。因此,除了发送的数据(即消息队列)外,邮箱的实现还需维护由 put() 存入的消息数据类型,以便进行运行时类型检查。
put() 方法的参数 message 可以是任何单一表达式,且必须是有效的左值表达式。get() 方法从邮箱中获取一条消息,即从邮箱队列中移除一条消息。如果邮箱为空,则当前进程会阻塞,直到有消息被放入邮箱。如果消息变量的类型与邮箱中消息的类型不匹配,将产生运行时错误。
通常情况下,邮箱用于传输特定类型的消息,此时在编译时检测类型不匹配会非常有用。
参数化邮箱采用与参数化类、模块和接口相同的参数机制:1
mailbox #(type = dynamic_type)
其中 dynamic_type 表示一种支持运行时类型检查的特殊类型(默认类型)。
通过指定类型可以声明特定类型的参数化邮箱:1
2
3
4
5
6typedef mailbox #(string) s_mbox;
s_mbox sm = new;
string s;
sm.put("hello");
...
sm.get(s); // s <- "hello"
参数化邮箱提供与动态邮箱完全相同的标准方法:num()、new()、get()、peek()、put()、try_get()、try_peek()、try_put()。
通用(动态)邮箱与参数化邮箱的唯一区别在于:对于参数化邮箱,编译器会验证对 put、try_put、peek、try_peek、get 和 try_get 方法的调用是否使用与邮箱类型等价的参数类型,从而确保所有类型不匹配问题在编译时被捕获,而非在运行时出现。
命名事件
被声明为事件数据类型的标识符称为命名事件。
- 命名事件可以被显式触发,并可用于事件表达式中,以控制过程语句的执行
- 命名事件也可作为从另一个命名事件分配的句柄使用。
- 当进程等待事件被触发时,该进程会被放入同步对象维护的队列中
- 进程可以通过
@运算符或使用wait()结构来检查其触发状态,从而等待命名事件被触发
触发事件
- 通过
->运算符触发的命名事件会解除当前所有等待该事件的进程阻塞。当被触发时,命名事件的行为类似于单次触发,即触发状态本身不可观测,只能观察到其效果。这与边沿触发触发器的方式类似,但无法确认边沿的状态,例如if (posedge clock)是非法的。 - 非阻塞事件使用
->>运算符触发。->>运算符的效果是语句以非阻塞方式执行,并在延迟控制到期或事件控制发生时,创建一个非阻塞赋值更新事件。该更新事件的作用是在仿真周期的非阻塞赋值区域触发所引用的事件。
等待事件
等待事件触发的基本机制是通过事件控制操作符 @ 实现的。语法为:@ hierarchical_event_identifier;。
@操作符会阻塞调用进程,直到指定的事件被触发- 要使触发操作解除对等待进程的阻塞,等待进程必须在触发进程执行触发操作符
->之前执行@语句。如果触发操作先执行,则等待进程会继续保持阻塞状态。
持久触发
SystemVerilog 能够区分瞬时的事件触发本身与命名事件的触发状态(该状态在整个时间步内持续存在,即持续到仿真时间推进)。命名事件的 triggered 内置方法允许用户检测这一状态。triggered() 方法的原型如下:1
function bit triggered();
如果在当前时间步内给定事件已被触发,则 triggered 方法返回 true(1'b1),否则返回 false(1'b0)。若命名事件为空,则 triggered 方法返回 false。
triggered 方法在 wait 结构中使用时最为有效:1
wait ( hierarchical_event_identifier.triggered )
通过这种机制,无论 wait 操作在触发操作之前执行,还是在同一仿真时间执行,事件触发都会解除等待进程的阻塞。因此,triggered 方法有助于消除触发与等待同时发生时常见的竞争条件。一个阻塞等待事件的进程是否解除阻塞,取决于等待进程与触发进程的执行顺序;而一个等待触发状态的进程则总能解除阻塞,不受等待与触发操作执行顺序的影响。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16event done, blast; // 声明两个新事件
event done_too = done; // 声明 done_too 是 done 的别名
task trigger( event ev );
-> ev;
endtask
...
fork
@ done_too; // 通过 done_too 等待 done
#1 trigger( done ); // 触发 done
join
fork
-> blast;
wait ( blast.triggered );
join
示例中两个事件标识符 done 和 done_too 指向同一个同步对象,事件可以传递给触发该事件的通用任务。在此示例中,一个进程通过 done_too 等待事件,而实际的触发操作则通过传递 done 作为参数的触发任务完成。
在第二个分支中,一个进程可能在另一个进程(如果分支中的进程按源代码顺序执行)有机会执行并等待事件之前触发事件 blast。尽管如此,第二个进程仍会解除阻塞,且分支会终止。这是因为进程等待的是事件的触发状态,该状态在当前时间步长内会保持触发状态。
事件表达式或等待条件仅在表达式中操作数发生变化时(例如 triggered 方法的事件前缀)才会重新求值。这意味着在当前时间步长结束时,triggered 方法的返回值从 1'b1 变为 1'b0 不会影响正在等待 triggered 方法的事件控制或等待语句。
wait_order
wait_order 结构会挂起调用进程,直到所有指定的事件按照给定顺序(从左到右)被触发,或者任一尚未触发的事件在顺序之外被触发,从而导致操作失败。
为使 wait_order 成功执行,在序列中的任意时刻,后续事件(此时必须全部处于未触发状态,否则序列早已失败)必须按照指定顺序触发。先前事件的发生次数不受限制。换言之,一旦某个事件按指定顺序出现后,即使再次被触发也不会导致结构失败。只有列表中的首个事件可以等待持续触发型事件。
该结构失败时的处理方式取决于是否指定了可选的 action_block else 语句(即失败处理语句)。若已指定,则结构失败时将执行给定语句;若未指定失败处理语句,则失败会引发运行时错误。1
wait_order( a, b, c );
该语句会挂起当前进程,直到事件 a、b、c 按 a→b→c 的顺序触发。若事件触发顺序错乱,将产生运行时错误。1
wait_order( a, b, c ) else $display( "Error: events out of order" );
此例中,失败处理语句规定结构失败时显示用户提示信息,且不生成错误报告。1
2bit success;
wait_order( a, b, c ) success = 1; else success = 0;
此例将执行状态存储于变量success中,且不生成错误报告。
命名事件合并
当一个事件变量被赋予另一个事件变量时,两者将合并。因此,对任一事件变量执行->操作都会影响正在等待这两个事件变量的进程。1
2
3
4
5
6
7
8event a, b, c;
a = b;
-> c; // 同时触发b
-> a; // 同时触发b和c
b = a;
-> a; // 同时触发a和c
-> b; // 同时触发a和c
-> c; // 同时触发a和b
当事件被合并时,赋值操作仅影响后续事件控制或等待操作的执行。若某进程因等待 event1 而阻塞,此时若有另一事件被赋值给 event1,则当前等待的进程将永远无法解除阻塞。1
2
3
4
5
6
7
8fork
T1: forever @ E1;
T2: forever @ E2;
T3: begin
E1 = E2;
forever -> E1;
end
join
此示例创建了三个并发进程。所有进程同时启动。因此,当进程 T1 和 T2 被阻塞时,进程 T3 同时将事件 E2 赋值给 E1。这将导致进程 T1 永远无法解除阻塞,因为事件 E1 此时已等同于 E2。若要使线程 T1 和 T2 均能解除阻塞,必须在 fork 操作之前完成 E2 与 E1 的合并。
事件回收
当事件变量被赋予特殊的空值(null)时,该事件变量与底层同步队列之间的关联将被解除。当没有事件变量与底层同步队列关联时,队列本身的资源即可被重新利用。
触发空事件不会产生任何效果。等待空事件的结果是未定义的,实现时可以发出运行时警告。1
2
3
4event E1 = null;
@ E1; // 未定义:可能永久阻塞或立即通过
wait( E1.triggered ); // 未定义
-> E1; // 无效果
事件比较
事件变量可与其他事件变量或特殊值 null 进行比较。仅允许对事件变量使用以下比较运算符:
- 与另一事件或
null的相等性比较(==) - 与另一事件或
null的不等性比较(!=) - 与另一事件或
null的全等比较(===)(语义与==相同) - 与另一事件或
null的非全等比较(!==)(语义与!=相同) - 布尔值测试:若事件为
null则结果为 0,否则为 1
1 | |
第十四章 断言
第十五章 检查块
第十六章 约束随机值生成
约束语句块
分布(Distribution)
分布是一种加权值集合。分布具有两个特性:一是作为集合成员资格的关系测试,二是为结果指定统计分布函数。
- 分布内的表达式可以是任何整型表达式
- 如果表达式的值包含在集合中,则分布运算符
dist的求值结果为真;否则结果为假 - 在没有其他约束的情况下,表达式匹配列表中任意值的概率与其指定的权重成正比
- 如果某些表达式存在约束,导致这些表达式的分布权重无法满足,仅需满足约束条件即可。此规则的一个例外是权重为零的情况,该情况被视为约束处理。
- 分布集是由整型表达式和范围组成的逗号分隔列表。列表中的每个项可以选择性地指定权重,使用
:=或:/运算符进行定义。若未指定项的权重,则默认权重为:= 1。权重可以是任何整型表达式。 :=运算符将指定权重分配给该项,若该项为范围,则分配给范围内的每个值:/运算符将指定权重分配给该项,若该项为范围,则将该权重作为整体分配给范围
1 | |
表示 x 等于 100、200 或 300,其加权比例为 1-2-5。如果增加一个额外约束,规定 x 不能为 200,即 x != 200;那么 x 等于 100 或 300,加权比例为 1-5。
当权重应用于范围时,可以应用于范围内的每个值,也可以应用于整个范围。例如:1
x dist { [100:102] := 1, 200 := 2, 300 := 5}
表示x等于100、101、102、200或300,加权比例为1-1-1-2-5;而1
x dist { [100:102] :/ 1, 200 := 2, 300 := 5}
表示x等于100、101、102、200或300中的一个,加权比例为1/3-1/3-1/3-2-5。
限制如下:
dist操作不得应用于 randc 变量。dist表达式要求该表达式至少包含一个 rand 变量。
第十七章 功能覆盖率
第十八章 工具系统任务和系统函数
第十九章 输入/输出系统任务与系统函数
第二十章 编译器指令
第二十一章 模块(Module)层级结构
第二十二章 程序(Program)
程序块常用于构建测试平台。对于测试平台而言,重点不在于硬件级别的细节(如连线、结构层次和互连),而在于建模用于验证设计的完整环境。该环境必须正确初始化和同步,避免设计与测试平台之间的竞争,自动生成输入激励,并复用现有模型及其他基础设施。程序块具有以下三个基本用途:
- 为测试平台的执行提供入口点。
- 创建一个封装程序范围数据、任务和函数的作用域。
- 提供语法上下文,用于指定在响应区域集中的调度。
程序结构作为设计与测试平台之间的清晰分隔,更重要的是,它为程序中声明的所有元素规定了响应区域集中的专用执行语义。结合时钟块,程序结构实现了设计与测试平台之间的无竞争交互,并支持周期级和事务级抽象。
程序结构
典型的程序包含类型和数据声明、子程序、与设计的连接以及一个或多个过程代码流。设计与测试平台之间的连接使用与指定端口连接(包括接口)相同的互连机制。程序端口声明的语法和语义与模块相同。1
2
3program test (input clk, input [16:1] addr, inout [7:0] data);
initial ...
endprogram
程序结构可被视为具有特殊执行语义的叶子模块。一旦声明,程序块即可在所需的层次结构位置(通常在顶层)实例化,其端口连接方式与其他模块完全相同。程序块可嵌套在模块或接口内部,这使得多个协作程序能够共享作用域内的局部变量。对于无端口的嵌套程序或未显式实例化的顶层程序,系统会对其进行一次隐式实例化。隐式实例化的程序具有相同的实例名称与声明名称。例如:1
2
3
4
5
6
7
8
9module test(...);
int shared; // 可在 p1 和 p2 内访问的共享变量
program p1;
...
endprogram
program p2;
...
endprogram // p1 和 p2 都被隐式实例化了
endmodule
- 一个程序块可以包含一个或多个 initial 块或 final 块
- 程序块不应包含
always过程、原语、UDP 或模块、接口或其他程序的声明或实例 - 当程序内的所有初始过程都结束时,该程序应立即终止其内部所有初始过程派生的子线程
- 如果至少有一个程序块中包含至少一个初始过程,则当所有程序中所有初始过程产生的线程及其派生线程全部结束后,整个仿真将通过隐式调用
$finish系统任务立即终止。 - 程序内的类型和数据声明仅限于程序作用域内,并具有静态生命周期
- 在程序作用域内声明的变量(包括声明为端口的变量)称为程序变量;在程序作用域内声明的线网称为程序线网。程序变量和程序线网统称为程序信号。
- 程序信号的对立面是设计信号。在模块、接口、包或
$unit中声明的任何线网或变量均被视为设计信号。 - 从任何程序块外部引用程序信号是错误的。从一个程序作用域到另一个程序作用域进行层次引用是合法的。然而,匿名程序不应包含对其他程序作用域的层次引用。
调度策略
程序代码中的非阻塞赋值会在 Re-NBA 区域中调度其更新。Re-NBA 区域会在 Reactive 和 Re-Inactive 区域中的事件全部处理完毕后执行。程序块中允许使用并发断言。无论出现在程序代码还是设计代码中,并发断言都具有不变的调度语义——断言始终在处理 Preponed 区域时对可用值进行采样,并在处理Observed区域时进行评估。若断言由程序对象的活动触发时钟(不推荐此做法),调度器将根据调度图所示的外层循环,从反应区域集开始迭代,经过 Observed 区域以完成断言评估。
一旦程序进程启动执行线程,该线程中所有后续的阻塞语句都将在 Reactive 区域中调度。这包括线程调用的子程序代码,即使子程序代码声明于模块、程序包或接口中。实际上,设计或测试平台中任意位置的顺序代码段都会继承调用线程的调度区域。由于模块代码永远不会调用程序代码,程序代码始终作为反应集处理的一部分执行。而模块、接口或程序包范围内的代码,则可能作为活动区域集或反应集处理的一部分执行。
第二十三章 接口(Interface)
SystemVerilog 中的接口结构是为封装模块间通信而创建,能够支持从抽象系统级设计到低层级寄存器传输级及结构级设计的平滑迁移。通过封装模块间通信,接口结构还促进了设计重用。
- 接口是一组具有名称的线网或变量集合
- 接口可在设计中实例化,并能作为单一单元通过端口访问,其包含的线网或变量可在需要时被引用
- 接口可包含参数、常量、变量、函数和任务,其内部元素类型可被声明,也可通过参数传入
- 成员变量和函数需通过接口实例名作为实例成员进行引用
- 通过接口连接的模块可直接调用该接口的子程序成员来驱动通信
- modport 结构提供模块端口的方向信息并控制特定模块内任务和函数的使用
- 除了子程序方法外,接口还可包含进程(如 initial 或 always 过程块)和连续赋值语句,这对系统级建模和测试平台应用非常有用
- 接口可在模块(扁平或层次化模块)中声明和实例化,但模块既不能在接口中声明也不能在接口中实例化。接口永远不会被隐式实例化。
简单的接口声明形式如下(完整语法参见语法规范25-1):1
2
3
4
5interface identifier;
...
interface_items
...
endinterface [ : identifier ]
接口可像模块一样进行层次化实例化,无论是否包含端口。例如:1
myinterface #(100) scalar1(), vector[9:0]();
此例实例化了 11 个 myinterface 类型接口,每个接口的首个参数均被修改为 100。其中名为 scalar1 的实例为单个接口,而 vector[9] 至 vector[0] 则构成了包含 10 个接口的实例数组。
基础用法
接口最简单的形式是一组变量或线网的集合。当接口作为端口被引用时,其中的变量和线网分别被视为具有 ref 和 inout 访问权限。以下接口示例展示了定义、实例化及连接接口的基本语法。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24interface simple_bus; // 定义接口
logic req, gnt;
logic [7:0] addr, data;
logic [1:0] mode;
logic start, rdy;
endinterface: simple_bus
module memMod(simple_bus a, // 访问 simple_bus 接口
input logic clk);
logic avail;
// a.req 是 sb_intf 实例中的 req 信号
always @(posedge clk) a.gnt <= a.req & avail;
endmodule
module cpuMod(simple_bus b, input logic clk);
...
endmodule
module top;
logic clk = 0;
simple_bus sb_intf(); // 例化接口
memMod mem(sb_intf, clk); // 连接接口到模块
cpuMod cpu(.b(sb_intf), .clk(clk)); // 按位置或按名称连接
endmodule
带端口列表的接口
简单接口的一个局限在于,其内部声明的线网与变量仅用于连接具有相同线网与变量的端口。若要共享外部线网或变量(即建立从接口外部接入的连接,并为所有实例化该接口的模块端口形成公共连接)则必须进行接口端口声明。接口端口列表中的线网或变量与接口内其他线网或变量的区别在于:当接口被实例化时,只有端口列表中的成员才能通过名称或位置进行外部连接。接口端口声明的语法和语义与模块的端口声明完全相同。1
2
3interface i1 (input a, output b, inout c);
wire d;
endinterface
线网 a、b 和 c 可以分别连接到接口,从而与其他接口共享。以下示例展示了如何定义带有输入信号的接口,使得一个线网可以在接口的两个实例之间共享:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26interface simple_bus (input logic clk); // 定义接口
logic req, gnt;
logic [7:0] addr, data;
logic [1:0] mode;
logic start, rdy;
endinterface: simple_bus
module memMod(simple_bus a); // 仅使用接口
logic avail;
always @(posedge a.clk) // 来自接口的 clk 信号
a.gnt <= a.req & avail; // a.req 位于 simple_bus 接口中
endmodule
module cpuMod(simple_bus b);
...
endmodule
module top;
logic clk = 0;
simple_bus sb_intf1(clk); // 实例化接口
simple_bus sb_intf2(clk); // 实例化接口
memMod mem1(.a(sb_intf1)); // 将 simple_bus 1 连接到内存 1
cpuMod cpu1(.b(sb_intf1));
memMod mem2(.a(sb_intf2)); // 将 simple_bus 2 连接到内存 2
cpuMod cpu2(.b(sb_intf2));
endmodule
带限制的接口(modport)
为了限制模块内接口的访问,接口内部声明了带有方向的 modport 列表。关键字 modport 表明这些方向的声明方式类似于在模块内部进行声明。
- 如果在端口连接中,模块实例和模块头部声明都指定了 modport 列表名称,那么这两个 modport 列表名称必须完全相同
- modport 声明中使用的所有名称,都应由与该 modport 本身相同的接口进行声明。具体而言,所使用的名称不应是由其他外层接口声明的名称,并且 modport 声明不应隐式声明新的端口。
1 | |
也可以在实例化模块的时候直接指定 modport:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26interface simple_bus (input logic clk);
logic req, gnt;
logic [7:0] addr, data;
logic [1:0] mode;
logic start, rdy;
modport slave (input req, addr, mode, start, clk, output gnt, rdy, ref data);
modport master(input gnt, rdy, clk, output req, addr, mode, start, ref data);
endinterface: simple_bus
module memMod(simple_bus a);
logic avail;
always @(posedge a.clk)
a.gnt <= a.req & avail;
endmodule
module cpuMod(simple_bus b);
...
endmodule
module top;
logic clk = 0;
simple_bus sb_intf(clk);
initial repeat(10) #10 clk++;
memMod mem(sb_intf.slave);
cpuMod cpu(sb_intf.master);
endmodule
甚至可以在 memMod 和 cpuMod 中使用通用端口类型:1
2
3
4
5
6
7
8
9module memMod(interface a);
logic avail;
always @(posedge a.clk)
a.gnt <= a.req & avail;
endmodule
module cpuMod(interface b);
...
endmodule
使用表达式的 modport
modport 表达式允许将接口中声明的数组元素、结构体元素、元素级联以及元素赋值模式表达式包含在 modport 列表中。该 modport 表达式通过端口标识符显式命名,仅能通过 modport 连接可见。与模块端口声明中显式命名的端口类似,端口标识符在每个 modport 列表中拥有独立的命名空间。当 modport 项仅为简单端口标识符时,该标识符既作为接口项的引用,也作为端口标识符使用。端口标识符一旦被定义,不得再出现同名端口定义。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18interface I;
logic [7:0] r;
const int x=1;
bit R;
modport A (output .P(r[3:0]), input .Q(x), R);
modport B (output .P(r[7:4]), input .Q(2), R);
endinterface
module M ( interface i);
initial i.P = i.Q;
endmodule
module top;
I i1 ();
M u1 (i1.A);
M u2 (i1.B);
initial #1 $display("%b", i1.r); // 输出 00100001
endmodule
端口表达式的自决类型成为端口的类型。端口表达式不应被视为类赋值上下文。端口表达式应解析为模块端口类型的合法表达式。在前述示例中,Q 端口不能是输出或双向端口,因为端口表达式是常量。端口表达式是可选的,因为可以定义不连接到端口内部任何内容的端口。
时钟块
modport 结构可用于指定接口内声明的时钟块的方向。
- 与其他 modport 声明类似,时钟块的方向是从将接口作为端口的模块视角观察的方向
- 在 modport 声明中使用的所有时钟块必须由与 modport 本身相同的接口声明
1 | |
接口中的任务与函数
- 子程序(任务和函数)可以在接口内部定义,也可以在连接的一个或多个模块内部定义
- 函数原型指定了在其他地方定义的函数的参数类型、方向以及返回值
- 任务原型指定了在其他地方定义的任务的参数类型和方向
- 在 modport 中,导入和导出结构可以使用子程序原型,也可以仅使用标识符
- 当 modport 用于从另一个模块导入子程序,或者使用默认参数值或按名称绑定参数时,在这种情况下必须使用完整的原型
- 原型中的参数数量和类型必须与子程序声明中的参数类型匹配
- 如果在子程序调用中需要默认参数值,则必须在原型中指定
- 如果参数在原型和声明中都指定了默认值,指定的值不必相同,但使用的默认值应是原型中指定的值
- 原型中的形式参数名称是可选的,除非使用默认参数值、按名称绑定参数或声明了额外的未打包维度
- 原型中的形式参数名称应与声明中的形式参数名称相同
- 如果一个模块连接到包含导出子程序的 modport,而该模块未定义该子程序,则会发生错误
- 如果 modport 包含导出的子程序原型,而模块中定义的子程序与该原型不完全匹配,也会发生错误
- 如果子程序使用层次名称在模块中定义,则还必须在接口中声明为 extern,或在 modport 中声明为 export。
- 任务(非函数)可以在被实例化两次的模块中定义,例如,由同一 CPU 驱动的两个存储器。接口中的 extern forkjoin 声明允许此类多重任务定义。
在接口中定义的任务示例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38interface simple_bus (input logic clk);
logic req, gnt;
logic [7:0] addr, data;
logic [1:0] mode;
logic start, rdy;
task masterRead(input logic [7:0] raddr);
// ...
endtask: masterRead
task slaveRead;
// ...
endtask: slaveRead
endinterface: simple_bus
module memMod(interface a);
logic avail;
always @(posedge a.clk)
a.gnt <= a.req & avail
always @(a.start)
a.slaveRead;
endmodule
module cpuMod(interface b);
enum {read, write} instr;
logic [7:0] raddr;
always @(posedge b.clk)
if (instr == read)
b.masterRead(raddr);
...
endmodule
module top;
logic clk = 0;
simple_bus sb_intf(clk);
memMod mem(sb_intf);
cpuMod cpu(sb_intf);
endmodule
在 modport 中导入任务(从模块方向看任务是被导出给模块)示例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68interface simple_bus (input logic clk);
logic req, gnt;
logic [7:0] addr, data;
logic [1:0] mode;
logic start, rdy;
modport slave (
input req, addr, mode, start, clk,
output gnt, rdy, ref data,
import slaveRead, slaveWrite
);
modport master(
input gnt, rdy, clk,
output req, addr, mode, start, ref data,
import masterRead, masterWrite
);
task masterRead(input logic [7:0] raddr);
// ...
endtask
task slaveRead;
// ...
endtask
task masterWrite(input logic [7:0] waddr);
//...
endtask
task slaveWrite;
//...
endtask
endinterface: simple_bus
module memMod(interface a);
logic avail;
always @(posedge a.clk)
a.gnt <= a.req & avail;
always @(a.start)
if (a.mode[0] == 1'b0)
a.slaveRead;
else
a.slaveWrite;
endmodule
module cpuMod(interface b);
enum {read, write} instr;
logic [7:0] raddr = $random();
always @(posedge b.clk)
if (instr == read)
b.masterRead(raddr);
// ...
else
b.masterWrite(raddr);
endmodule
module omniMod( interface b);
//...
endmodule: omniMod
module top;
logic clk = 0;
simple_bus sb_intf(clk);
memMod mem(sb_intf.slave);
cpuMod cpu(sb_intf.master);
omniMod omni(sb_intf);
endmodule
在 modport 中导出任务(从模块方向看任务是被导入给接口)示例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54interface simple_bus (input logic clk);
logic req, gnt;
logic [7:0] addr, data;
logic [1:0] mode;
logic start, rdy;
modport slave(
input req, addr, mode, start, clk,
output gnt, rdy,
ref data,
export Read, Write
);
modport master(
input gnt, rdy, clk,
output req, addr, mode, start,
ref data,
import task Read(input logic [7:0] raddr), task Write(input logic [7:0] waddr)
);
endinterface: simple_bus
module memMod(interface a);
logic avail;
task a.Read;
avail = 0;
...
avail = 1;
endtask
task a.Write;
avail = 0;
...
avail = 1;
endtask
endmodule
module cpuMod(interface b);
enum {read, write} instr;
logic [7:0] raddr;
always @(posedge b.clk)
if (instr == read)
b.Read(raddr);
...
else
b.Write(raddr);
endmodule
module top;
logic clk = 0;
simple_bus sb_intf(clk);
memMod mem(sb_intf.slave);
cpuMod cpu(sb_intf.master);
endmodule
在一个 modport 中导出的任务(实际上是在该 modport 连接到的模块中定义任务)可以传递到另一个 modport 中导入(实际上是在该 modport 连接到的模块中调用任务),modport 起到了子程序的连接作用。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21interface tlm_intf();
modport sender_mp(import task put(input byte b));
modport receiver_mp(export task put(input byte b));
endinterface
module tlm_sender (tlm_intf.sender_mp send_port);
initial
send_port.put("n");
endmodule
module tlm_receiver (tlm_intf.receiver_mp receive_port);
task receive_port.put(input byte b);
$display("i got data =%0d",b);
endtask
endmodule
module test;
tlm_intf tlm_int0();
tlm_sender tlm_sender0(tlm_int0.sender_mp);
tlm_receiver tlm_receiver0(tlm_int0.receiver_mp);
endmodule
参数化接口
接口定义可以采用与模块定义相同的方式利用参数和参数重定义。1
2
3
4
5
6
7
8
9interface simple_bus #(
AWIDTH = 8, DWIDTH = 8
) (input logic clk);
logic req, gnt;
logic [AWIDTH-1:0] addr;
logic [DWIDTH-1:0] data;
logic [1:0] mode;
logic start, rdy;
endinterface: simple_bus
注意:参数化接口在实例化时不允许跳过排在前面的参数。1
2
3simple_bus #(16,4) buss(clk); // dwidth = 16, awidth = 4
simple_bus #(16) buss(clk); // dwidth = 16, awidth = 8
simple_bus #( ,4) buss(clk); // 错误!
虚拟接口
虚拟接口提供了一种机制,用于将抽象模型和测试程序与构成设计的实际信号分离开来。虚拟接口允许同一子程序对设计的不同部分进行操作,并动态控制与该子程序相关联的信号集。用户无需直接引用实际信号集,而是能够操作一组虚拟信号。即使底层设计发生变化,使用虚拟接口的代码也无需重写。通过抽象一组模块的连接性和功能,虚拟接口促进了代码的重用。
- 虚拟接口是一种表示接口实例的变量
- 虚拟接口变量可以作为参数传递给任务、函数或方法
- 在仿真过程中,单个虚拟接口变量可以在不同时间代表不同的接口实例(一般情况下类型是相同的)
- 虚拟接口在引用其组件前必须进行初始化,未初始化时其值为空
- 接口类型应包含实际参数(无论是默认参数还是被覆盖的参数),这些参数用于接口的实例化或虚拟接口变量的声明
- 要使接口与虚拟接口属于同一类型且具备赋值兼容性,这些参数的实际值和类型必须匹配
- 虚拟接口声明可以选择接口的调制端口(modport),此时该调制端口也成为其类型的一部分
- 未选择调制端口的接口实例或虚拟接口可以赋值给已选择调制端口的虚拟接口。
- 若存在对接口实例或接口层次结构参数的默认参数赋值(defparam),且该默认参数赋值语句声明在接口外部,则禁止将接口实例赋值给虚拟接口
- 尽管接口可能包含对其外部对象的层次化引用,或包含引用其他接口的端口,但在声明虚拟接口时使用包含此类引用的接口是非法的。
- 虚拟接口不得用作端口、接口项或联合体成员
- 一旦虚拟接口被初始化,其底层接口实例的所有组件均可通过点操作符直接访问。这些组件仅能在过程语句中使用,不可用于连续赋值或敏感列表中
- 若要通过虚拟接口驱动线网,接口本身必须提供相应的过程化方法,这可以通过时钟块实现,或通过在接口内包含一个由变量连续赋值更新的驱动器来完成。
- 虚拟接口可声明为类的属性(一般情况下都是这样用的),并可通过过程化方式或
new()函数的参数进行初始化。这使得同一虚拟接口能够用于不同的类。以下示例展示了如何利用相同的传输器类与多种不同设备进行交互:
仅允许对虚拟接口变量直接进行以下操作:
- 赋值(
=)给以下对象:- 同一类型的另一个虚拟接口
- 同一类型的接口实例
- 特殊常量 null
- 相等(
==)与不等(!=)操作适用于以下情况:- 同一类型的另一个虚拟接口
- 同一类型的接口实例
- 特殊常量 null
第二十四章 包(Package)
SystemVerilog 包提供了一种额外的机制,用于在多个 SystemVerilog 模块、接口、程序和检查器之间共享参数、数据、类型、任务、函数、序列、属性和检查器声明。
- 包是显式命名的作用域,出现在源代码的最外层(与顶层模块和原语处于同一层级)
- 类型、线网、变量、任务、函数、序列、属性和检查器可以在包内声明
- 这些声明可以通过导入或完全解析名称的方式在模块、接口、程序、检查器以及其他包中引用
- 包仅允许在检查器内部包含进程
- 不允许使用带有隐式连续赋值的线网声明
- 包内的内容通常包括类型定义、任务和函数
- 包不得引用编译单元作用域中定义的项
- 包内的变量声明赋值应在任何初始过程或
always过程开始之前完成,其方式与在编译单元或模块中声明的变量相同 - 包的编译应先于导入该包的作用域的编译
引用包中的数据
- 使用包中声明的一种方式是通过包作用域解析运算符
::来引用它们。例如:ComplexPkg::Complex cout = ComplexPkg::mul(a, b); - 另一种利用包声明的方法是通过导入声明。
导入声明提供了包内标识符的直接可见性。它允许在当前作用域内直接访问包内声明的标识符,而无需使用包名限定符。导入声明提供两种形式:显式导入和通配符导入。显式导入仅导入导入语句明确引用的符号:1
2import ComplexPkg::Complex;
import ComplexPkg::add;
在以下示例中,对枚举类型 teeth_t 的导入并不会同时导入枚举字面量 ORIGINAL 和 FALSE。若要从包 q 中引用枚举字面量 FALSE,需额外添加 import q::FALSE,或使用完整包引用如 teeth = q::FALSE;。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25package p;
typedef enum { FALSE, TRUE } bool_t;
endpackage
package q;
typedef enum { ORIGINAL, FALSE } teeth_t;
endpackage
module top1;
import p::*;
import q::teeth_t;
teeth_t myteeth;
initial begin
myteeth = q::FALSE;
myteeth = FALSE; // 错误
end
endmodule
module top2 ;
import p::*;
import q::teeth_t, q::ORIGINAL, q::FALSE;
teeth_t myteeth;
initial begin
myteeth = FALSE; // OK: 已经导入,可以直接使用
end
endmodule
- 如果导入的标识符已在同一作用域内声明,或已从其他包中显式导入,则显式导入是非法的
- 允许从同一包中多次导入同一标识符
- 通配符导入允许导入包内声明的所有标识符,前提是该标识符未在导入作用域内另行定义
- 若在当前作用域内某点之前存在对某个包的通配符导入,且该包包含该标识符的声明,则该标识符在该作用域内该点处可能具有局部可见性。
- 标识符在作用域内某点处具有局部可见性的条件为:
- 该标识符表示当前作用域内的嵌套作用域;或
- 该标识符在当前作用域内该点之前已声明为标识符;或
- 该标识符通过当前作用域内该点之前的显式导入而可见。
- 若对标识符引用的解析未找到其他匹配的局部可见标识符,则通过通配符导入可能具有局部可见性的标识符可变为局部可见标识符
- 对于非函数或任务调用的标识符引用,应搜索当前作用域内引用点处定义的局部可见标识符。若引用为函数或任务调用,则应搜索当前作用域内直至作用域末尾的所有局部可见标识符。若找到匹配项,则引用应绑定至该局部可见标识符
- 若无局部可见标识符匹配,则应搜索当前作用域内引用点之前定义的可能具有局部可见性的标识符。若找到匹配项,则该包中的标识符应导入当前作用域,成为当前作用域内的局部可见标识符,且引用应绑定至该标识符
- 若引用未在当前作用域内绑定,则应搜索下一个外层词法作用域:首先搜索该作用域内的局部可见标识符,然后搜索引用点之前定义的可能具有局部可见性的标识符。若在可能具有局部可见性的标识符中找到匹配项,则该包中的标识符应导入外层作用域,成为外层作用域内的局部可见标识符
- 若通配符导入的符号在作用域内变为局部可见,则后续在该作用域内对同名的局部可见声明均属非法
- 应对外层词法作用域重复此搜索算法,直至找到与引用匹配的标识符,或再无外层词法作用域(编译单元作用域为最终搜索作用域)。对于非函数或任务调用的标识符引用,若未找到匹配的标识符,则属非法。若引用为函数或任务调用,则继续使用向上层次标识符解析进行搜索
- 若同一作用域内多个包的通配符导入定义了同一可能具有局部可见性的标识符,且对引用的搜索匹配该标识符,则属非法
第二十五章 生成构造
本博客所有文章除特别声明外,均采用 CC BY-NC-ND 4.0 协议 ,转载请注明出处!